Cloudflare 如何解决了 quiche 中的一个拥塞漏洞
点击查看原文>
最近,Cloudflare 分享了他们如何发现其 CUBIC(一种拥塞控制算法)的 Rust 实现中存在的一个问题。如果连接初始阶段出现了严重的数据包丢失,那么该问题会导致这个算法无法恢复。
该问题影响了他们的开源 Quick UDP Internet Connections(QUIC)实现库 quiche。这个库位于其所处理的大部分流量的关键路径上。团队将该问题追溯到了 Linux 内核中一项修复 TCP 问题的变更。
Cloudflare 系统工程师 Esteban Carisimo 和首席系统工程师 Antonio Vicente 解释说,他们的调查源于一份关于入站代理集成测试管道中出现意外故障的报告。所有失败的测试都有一个共同点:它们都是在连接初始阶段丢包率极高的场景下对 CUBIC 进行评估。
正如作者所解释的那样,CUBIC 及其他基于丢包率的算法基于一个基本的前提:
(1) 如果没有数据包丢失,则提高发送速率(即提高带宽利用率);(2) 如果发生数据包丢失,那么基于丢包率的算法就会认为已经超过网络容量,发送方必须进行退避(即降低带宽利用率)。
为了更好地理解这个问题,该团队构建了一个模拟环境:在本地主机上运行 Quiche HTTP/3 客户端和服务器,采用 CUBIC 作为拥塞控制器,并将往返时间(RTT)配置为 10 毫秒。客户端通过 HTTP/3 下载了一个 10MB 大小的文件,并在前两秒内注入了 30% 的随机数据包丢失。根据估计,该测试将在大约四到五秒内完成,因此 10 秒的超时时间似乎相当宽裕。
模拟测试的结果证实了在失败的集成测试管道中观察到的情况:在多次各执行 100 次的测试中,约有 60% 的测试未能在 10 秒超时前完成。
该团队在其实现中加入了监控机制,用于收集有关故障行为的详细信息。他们注意到,在数据包丢失之后,拥塞窗口并没有像预期的那样扩大,也没有显示出任何恢复迹象。此外,监控数据显示,在没有数据包丢失的阶段,CUBIC 在“拥塞规避状态”和“恢复状态”之间进行着快速的状态转换。具体而言,约 6.7 秒内发生了 999 次状态转换:平均每 ~14 毫秒一次。研究团队认为,这一频率与为连接配置的 10 毫秒 RTT 值过于接近,令人起疑。
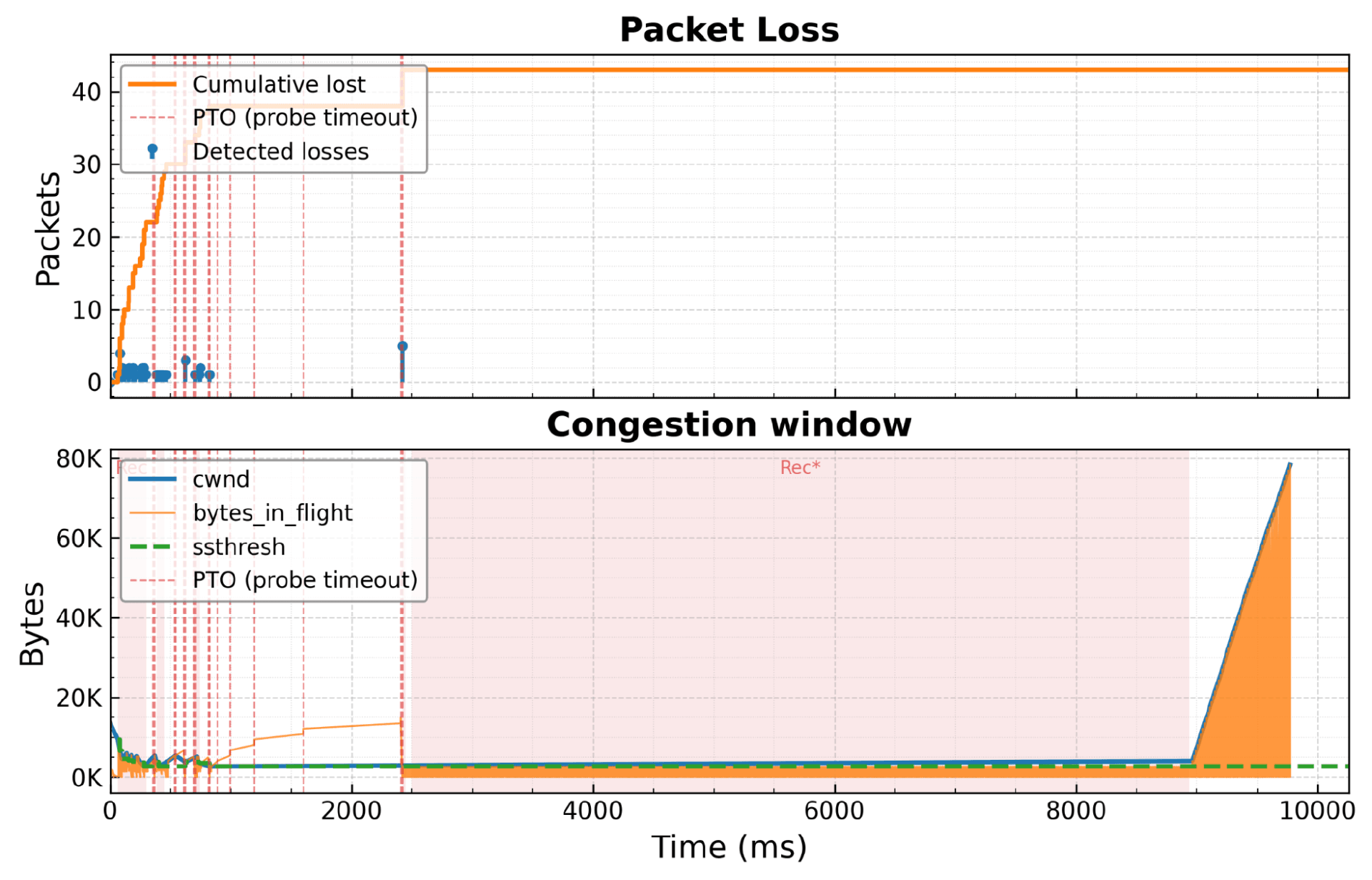
出现故障时累计数据包丢失率与拥塞窗口大小的对比(图片来源:Cloudflare 博客)
为了排除一个更广泛的问题,该团队还希望用另一种基于损失的拥塞控制算法 Reno 来取代 CUBIC。模拟的 Reno 测试 100% 通过,因此,问题范围限定在了 CUBIC 上。
根据该团队的说法,CUBIC 计算空闲时间的方式导致该实现陷入了一个无休止的恢复循环。在嘈杂的慢启动阶段,当传入的 ACK 数据包将传输中的字节数降为零时,该循环便会被触发。作者指出,当最小拥塞窗口为两个数据包时,空闲期优化便会变成一种“自我实现的预言”。该循环会将应用程序的状态维持在恢复状态,而且恢复时间被设定在遥远的未来,这阻碍了拥塞窗口的扩大。
据 Reddit 用户 RelevantKnowledge485 的描述,其他人也遇到了类似的问题:
我们在处理依赖定时器的高频工作负载时,也遇到了一个惊人相似的问题,当时 C 状态的切换导致了不可预测的延迟峰值。这里的调试方法——将内核的电源管理决策与协议层的重传行为相关联——确实非常可靠。
作者表示,这一探索最终取得了圆满的成功,而且与该行为的复杂性相比,解决方案相当简单。他们写道:
这是一个圆满的结局:一个(几乎)仅需一行代码的优雅的修复方案,成功打破了这一循环”。
团队不再从上次发送数据时开始计算空闲时间,而是开始从收到最后一个 ACK 时进行计算。
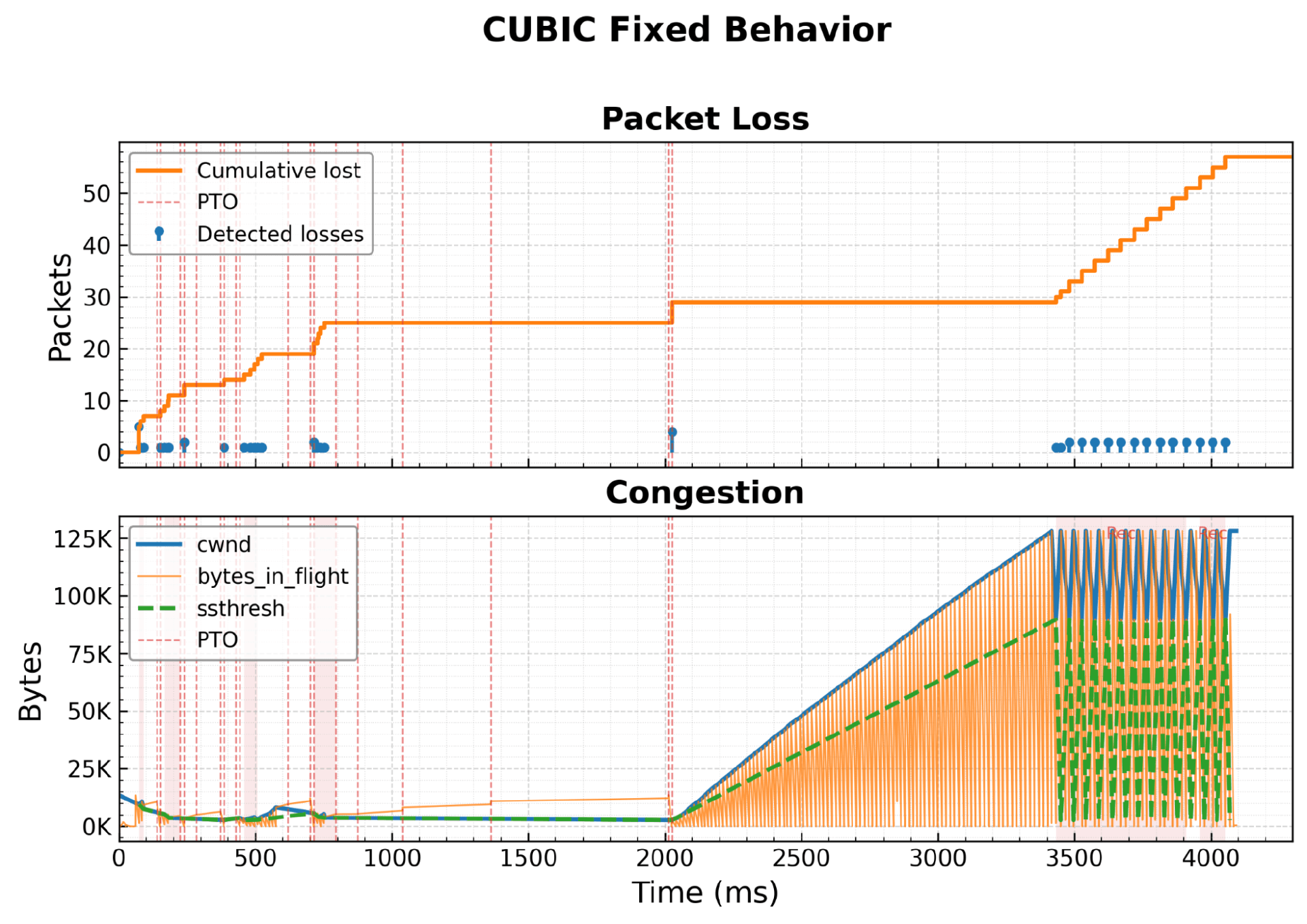
修复后的累积数据包丢失率与拥塞窗口大小的对比(图片来源:Cloudflare 博客)
这一修复措施足以打破循环,使拥塞窗口像预期的那样恢复,从而使测试通过率恢复到 100%。
原文链接:https://www.infoq.com/news/2026/06/cloudflare-bug-quiche/
本文来源:InfoQ