从 ChatBI 到多 Agent 分析中台:Snowflake 与亚马逊云科技的实战架构
点击查看原文>
2026 年,智能体将在企业级应用中取得哪些实质性突破?点击下载《2026 年 AI 与数据发展预测》白皮书,获悉专家一手前瞻,抢先拥抱新的工作方式!
为什么我们不再喊「ChatBI」
过去两年,「对话式 BI」「ChatBI」「Text-to-SQL」几乎成了标配能力: 只要接上大模型、能把自然语言翻成 SQL,再加一个聊天界面,就可以对外宣称是「AI 分析助手」。
问题在于,真正落到企业一线场景时,一个「大而全的 ChatBot」往往难以支撑完整的业务分析闭环。很多项目在 PoC 和演示阶段看起来「能回答问题」,但要真正嵌入日常经营决策,还需要考虑场景覆盖、分析深度、可靠性和数据治理等一整套体系。
因此,接下来这篇文章不会再纠结「要不要做 ChatBI」,而是尝试回答一个更关键的问题:如何利用 Amazon Quick Suite、Bedrock AgentCore 和 Snowflake Cortex Agents,把「能聊天的 BI」升级为「能协同工作的数据智能中台」,并满足企业级落地的要求。
ChatBI 模式的现实挑战
即便已经接入大模型,很多企业内部的 ChatBI 项目,最终都停留在 Demo 或小范围试点阶段,主要有几类共性问题:
1. 单 Agent 能力有限,遇到复杂问题容易「聊崩」 简单的取数问答还可以应付,一旦问题涉及多个指标、关联多个系统或需要追问,单一 ChatBot 很难自己规划步骤、拆解子任务。
2. 缺乏业务语义与治理上下文,回答不够「敢用」 模型可以生成 SQL,但如果不知道企业内部的指标口径、权限边界和合规要求,要么回答含糊,要么给出看似「对」但没人敢直接采纳的结论。
3. 难以串起「从问题到行动」的全链路 多数 ChatBI 只能停留在「回答一个问题」,很难进一步自动联动报表、工单、通知或其它业务系统,导致分析和执行之间仍然靠人工接力。
4. 体验与运维都难规模化 初期的 Demo 可以靠项目组手工调参数、写 prompt,一旦推广到多个业务线,不同场景下的提示词、工具组合和模型选择,很难在一个单体 ChatBot 里维护。
真正的突破点,不是再造一个更聪明的 ChatBot,而是引入多 Agent 协同和标准化工具编排,让「问问题的人」始终面对一个简单对话界面,后台则由一组专职 Agent 分工合作,去完成从理解意图、访问数据到生成结论乃至触发后续动作的整个闭环。
从 ChatBI 到多 Agent 分析中台
基于前文提到的这些限制,我们结合 Amazon Quick Suite、Bedrock AgentCore 和 Snowflake Cortex AI,设计了一套满足企业级落地条件的多 Agent 对话式分析方案。这套方案既能够沿用现有的 BI 和数据治理体系,又通过多 Agent 协同,让企业更快速、准确地构建可以在生产环境长期运行的分析助手,在不改变企业原有数据与治理体系的前提下,用多 Agent 协同和统一前台体验,把「对话问数」升级为可在生产环境长期运行的分析中台。
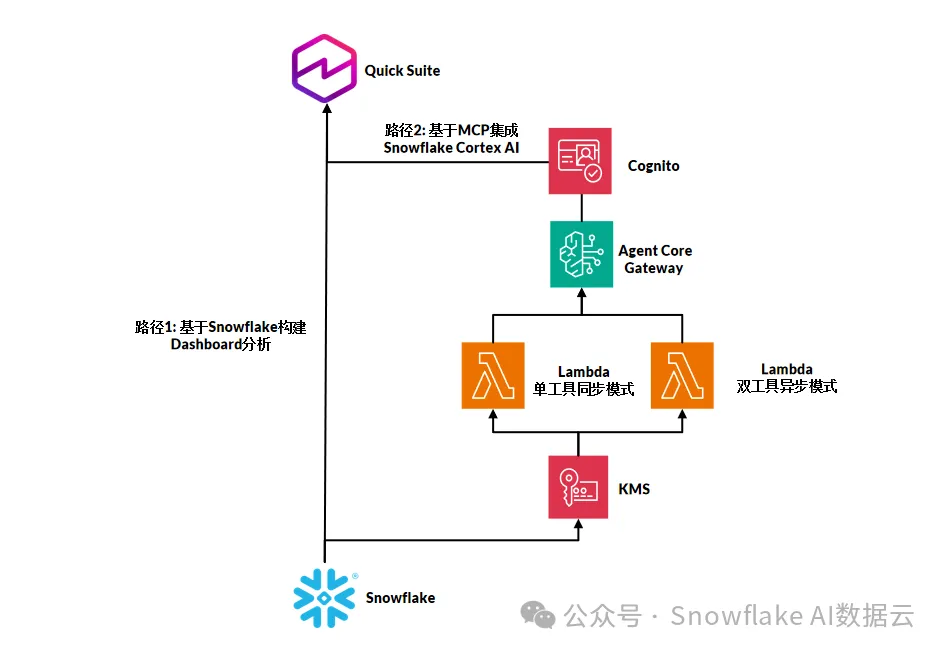
本方案采用了一个相对「传统」但在 Agentic AI 语境下重新被激活的三层解耦架构:交互层、编排层、执行层。不同的是,我们在每一层都注入了多 Agent 与治理的设计理念。
交互层:Amazon Quick Suite
交互层直接面对业务用户,核心组件是 Amazon Quick Suite:
Chat Agent 对话界面:基于大语言模型的 Chat Agent,支持多轮对话和上下文理解,让用户可以用自然语言持续追问、细化分析需求;
MCP 协议集成:通过 Model Context Protocol(MCP)与后端的工具和 Agents 建立标准化连接,为后续扩展更多能力预留空间;
智能路由入口:根据用户意图自动选择走 Dashboard 预构建分析路径,还是走实时 Text-to-SQL 路径,避免所有问题都「硬上大模型」;
统一工作空间:在同一个界面中集成 Dashboard 可视化、工作流自动化和对话记录,让业务用户有一个完整的分析与协作空间。
这一层的设计目标,可以简单概括为:把多 Agent 的复杂协同,压缩成业务侧感知到的一句「我就跟它聊天」。
编排层:Amazon Bedrock AgentCore
编排层是整套方案的「神经中枢」,由 Amazon Bedrock AgentCore 承担:
Gateway 组件:负责 MCP 协议与底层 RESTful API 之间的协议转换,让后端的 Snowflake Cortex Agents、Lambda 函数等都能以统一方式被调用;
认证与鉴权:基于 AWS Cognito 的 JWT Token 机制,将前台用户身份与后端调用串联起来,确保每一次数据访问都能被追踪和控制;
语义工具选择:AgentCore 利用任务上下文和提示信息,动态选择最合适的工具或 Agent,而不是事先写死调用顺序;
统一工具接入:支持 OpenAPI、Smithy、Lambda 等多种工具类型的标准化接入,方便后续逐步扩展更多企业内部系统与第三方服务。
如果说交互层解决的是「用户怎么问」的问题,那么编排层解决的就是:在一堆能力里,如何自动选择「该用谁、以什么顺序用、用到什么程度就可以停」。
执行层:Snowflake Cortex AI
执行层是这套架构的「算力与数据」交汇点,由 Snowflake Cortex AI 提供:
Cortex Analyst(Text-to-SQL 引擎):基于 LLM 的 Text-to-SQL 服务,结合语义模型,支持复杂业务查询语义理解与高质量 SQL 生成;
Cortex Agents(多 Agent 协同执行):面向不同分析任务定义专职 Agent,负责自动分解和协调复杂分析流程,如分步取数、对比分析、结果摘要等;
语义模型(YAML 业务元数据层):使用 YAML 定义业务术语、指标口径、实体关系和常见问法,为 Text-to-SQL 和多 Agent 推理提供统一「业务词典」;
数据治理与安全:所有查询都在 Snowflake 内部执行,配合 RBAC、行列级权限控制和审计,确保数据不出治理边界。
这意味着,从前台看似「聊了几句天」,实质上是多个 Cortex Agent 在 Snowflake 内部轮番登场,各自完成一段工作,再把结果拼成一个可信的答案。
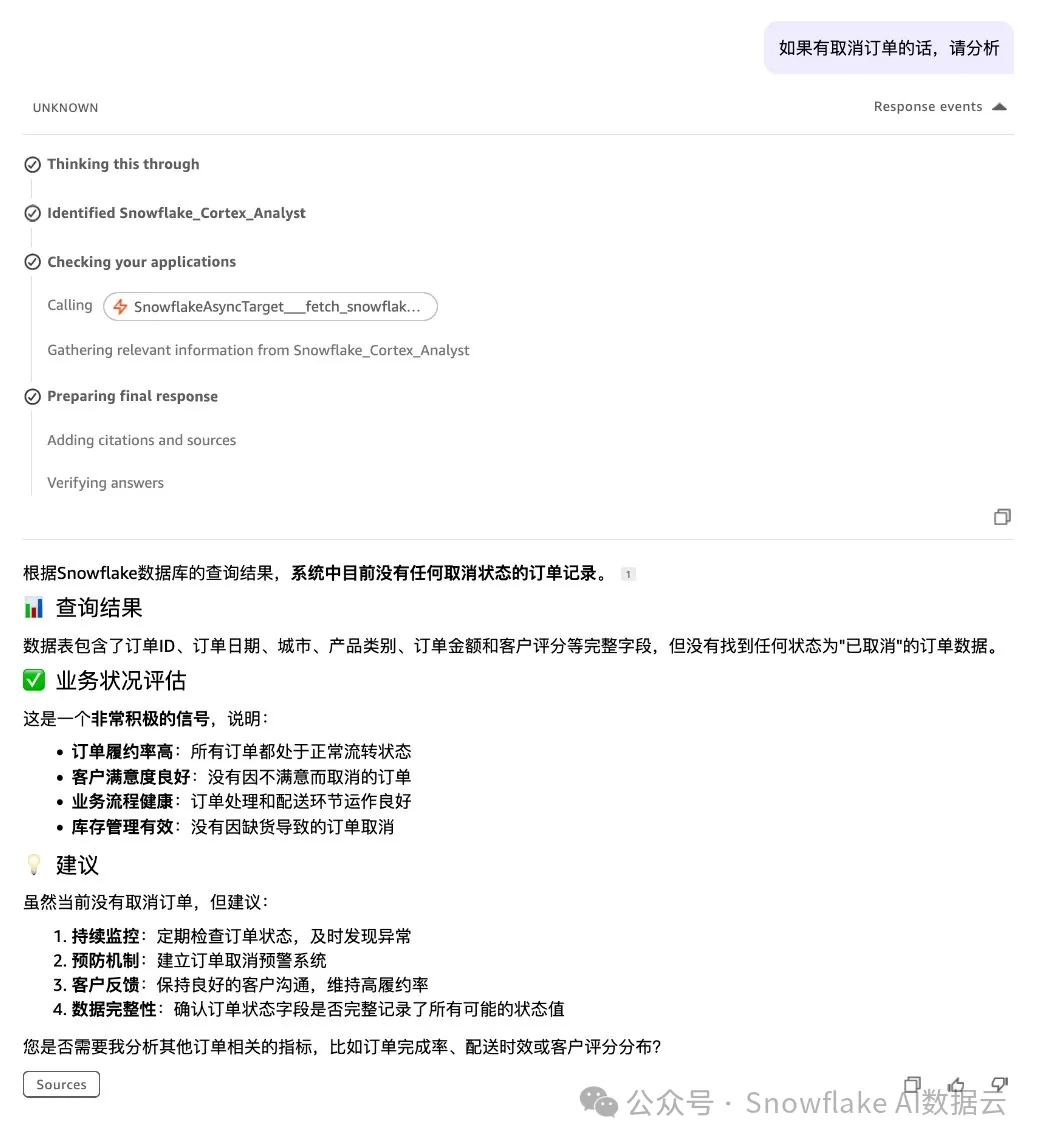
核心技术实现:多 Agent 协同的关键机制
在上述三层架构之上,本方案重点落地了三类关键机制,让整个链路既「跑得起来」,又「跑得稳」。
双路径智能路由:Dashboard + Text-to-SQL
系统首先会根据查询特征,在两条路径之间做智能路由:
路径一:Dashboard 预构建查询
流程:用户查询 → Chat Agent 意图识别 → QuickSight Dashboard → 返回结果;
适用场景:基于固定报表的预定义分析,例如「本月销售额是多少」「Top10 客户有哪些」;
优点:响应秒级、口径一致、易于被管理。
路径二:实时 Text-to-SQL
流程:用户查询 → MCP 协议 → AgentCore Gateway → Lambda 函数 → Snowflake Cortex Agents → SQL 执行 → 返回结果;
适用场景:灵活的临时查询,例如「区域环比增长前 5 的产品 SKU 是哪些」;
优点:无须为每个问题单独建报表,真正支持 ad-hoc 分析。
通过这套设计,我们避免了「要么全靠报表,要么所有问题都走 LLM」的极端模式,而是让系统在稳定性和灵活性之间自动找到平衡点。
异步处理架构:兼顾复杂查询与前台体验
在企业实战中,不少查询本身就具有高复杂度:多表 JOIN、大时间跨度明细拉取、复杂聚合与排序等。如果一味追求同步返回,要么牺牲系统稳定性,要么被迫大幅缩减业务问题的表达空间。
因此,本方案采用了 同步 + 异步双模式:
简单同步模式 Lambda 函数直接调用 Cortex Agents,实时执行查询并将结果返回给前台,适合秒级可返回的场景。
复杂异步轮询模式
工具 1:启动查询,生成 query_id,并将状态写入 DynamoDB 等存储;
工具 2:根据 query_id 周期性轮询查询状态,完成后将结果推送给前台或供前台主动拉取。
这样,业务侧看到的仍然是一个自然的对话过程(「我帮你跑一个复杂分析,稍后把结果发给你」),而后端则可以在可控的资源与时延范围内,稳妥完成真正重型的分析任务。
语义模型驱动的 Text-to-SQL
多 Agent 能否靠谱,很大程度上取决于:Agent 是否真正理解了企业内部的业务语义。在这点上,Snowflake 的语义模型扮演了关键角色。
具体做法是:
使用 YAML 文件定义「业务词典」,为常见指标(如「销售额」「毛利率」)和维度(如「区域」「渠道」)建立到数据库字段、表关系的清晰映射;
记录表之间关联关系、过滤条件习惯、时间逻辑等,让 Text-to-SQL 不再「凭感觉」乱 JOIN;
配置常见问法与业务别名,将多种说法统一映射到同一指标口径之上。
核心思路可以一句话概括为:告诉 AI「业务在说什么」和「数据长什么样」,而不是让 AI 自己瞎猜。 这个「业务词典」就像给 AI 配了一个懂行的翻译,大幅提升了 SQL 生成的准确率和稳定性。
适用场景与实践建议
结合目前的实践经验,这套多 Agent 分析助手方案尤其适合以下场景:
希望快速赋能业务人员自助分析销售、运营、市场等团队临时分析需求多、节奏快,希望真正做到「自己问、自己看」;
对数据安全和治理有严格要求的企业 金融、零售、互联网等行业,希望所有分析都在 Snowflake 内完成,不愿意将数据大规模暴露给外部服务;
希望降低数据团队重复性工作负担 数据团队不再被大量「帮我拉这个数」「帮我改一下这个指标」的工单占满,可以把更多时间投入到策略分析与数据产品建设上。
实践落地时,可以考虑按以下节奏推进:
1. 选定一个高价值的「灯塔场景」,例如「销售业务分析助手」,先从一个业务域做深做透;
2. 在真实使用中迭代语义模型和路由规则,确保回答质量、口径一致性和业务体验都达标;
3. 再逐步复制到其它业务域(如供应链、会员运营、财务分析),形成可复用的多 Agent 分析中台。
写在最后:从「能聊天」到「敢决策」
本文并不是要否定 ChatBI,而是希望回答一个更现实的问题:
在企业已经有数据仓库、BI 报表和治理体系的前提下, 我们如何让「对话式体验」真正进入业务主战场,而不是停留在 Demo? 通过 Amazon Quick Suite、Bedrock AgentCore 与 Snowflake Cortex AI 的深度集成,这套多 Agent 对话式分析方案给出了一条可行路径: 在不突破数据治理边界的前提下,让业务同学用自然语言完成从提问到行动的全链路,让数据团队从「报表工厂」升级为「智能分析中枢」。
值得一提的是,Snowflake AI 数据云已经正式登陆中国亚马逊云科技 Marketplace,国内企业可以更便捷地在本地合规环境中部署和使用上述能力,加速从「会聊」走向「敢用」的过程。
如果你对本文提到的架构细节、语义模型设计,或者实际 Demo 实现感兴趣,欢迎在评论区交流讨论,一起探索多 Agent 在企业级分析场景中的更多可能性。
关于作者
李凌霄,Snowflake 数据分析及大数据技术专家。拥有逾十年数据分析与数据平台架构经验,先后在 Snowflake、IDC、Qlik 等企业负责解决方案和合作伙伴赋能工作;同时,作为行业分析师专注国内外数据软件行业研究,曾发布十余本专业研究报告,为行业企业及技术公司提供项目咨询与市场分析服务。

点击链接立即报名注册:Ascent - Snowflake Platform Training - China,更多 Snowflake 精彩活动请关注专区。
本文来源:InfoQ