大规模工程支撑场景下的多智能体系统设计:Grab 实践案例
点击查看原文>
Grab 分析数据仓库(ADW)团队推出了一套多智能体 AI 系统,用于自动化大规模数据平台中的工程支持工作流,目标是减少重复性运维工作并提升问题解决效率。这套系统主要处理内部的工程请求,包括数据仓库故障排查、SQL 调试和平台支持等相关工作,帮助工程师将精力转向具有更高价值的开发工作。
ADW 平台服务超一千名内部用户,管理着 15000 多张数据表,是 Grab 核心分析基础设施的重要组成部分。随着使用量增长,工程团队发现大量运维精力被重复性支持任务和临时问题排查所消耗,挤占了平台优化迭代与系统架构设计的工作时间。
Grab 分析部门负责人 Sneh Agrawal 在 LinkedIn 帖子中指出:
Grab 中央数据团队正在利用多智能体系统实现重复性运维工作的自动化,每月可节省数百个工程工时。这一转变有效释放了核心工程人力,推动团队从被动应急处理的“救火”模式转向深耕高价值的系统构建工作。
为此,团队搭建了一个多智能体架构,将收到的工程请求划分成调查与增强两大核心工作流。调查工作流专门用于处理各类问题诊断工作,包括查询分析、日志检索、数据表结构查询以及问题整理汇总;增强工作流则专注于生成可执行的输出,如代码变更、SQL 修复和待审查的自动合并请求。
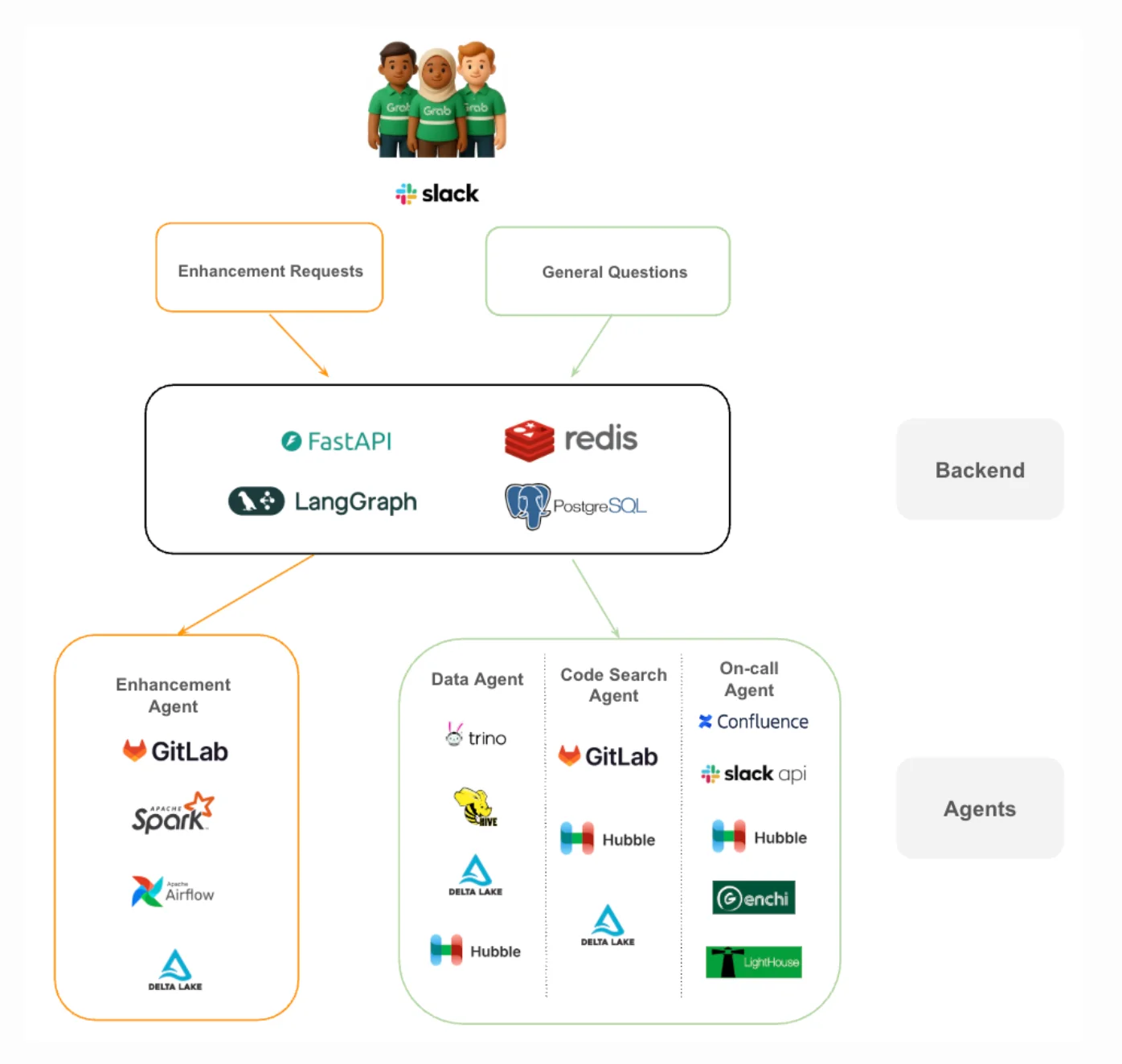
多智能体架构技术栈(来源:Grab 技术博客)
该系统采用基于 LangGraph 的工作流引擎进行编排,结合 FastAPI 服务,协调各智能体之间的路由、工具执行和状态管理。请求首先会被分类,然后路由至负责上下文检索、代码搜索或解决方案生成的专门智能体。每个智能体的职责受到严格约束,以便减少判定偏差,提升输出结果的稳定性。
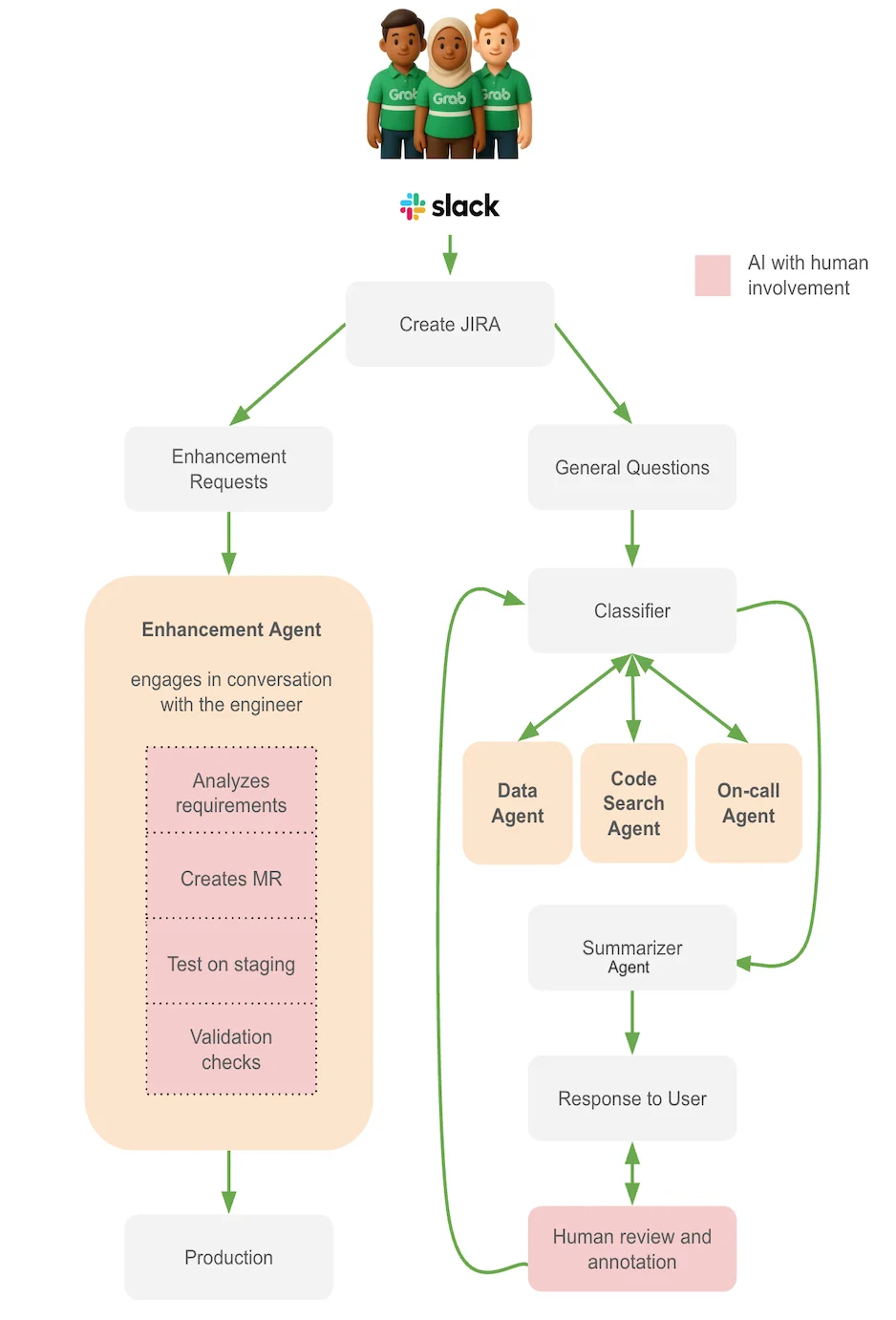
智能体工作流,使用 Supervisor 控制通信流和任务委派(来源:Grab 技术博客)
Grab 的工程师表示:
调查路径与增强路径的分离有效降低了智能体推理的复杂度,并提升了生产工作流的可靠性。
一项关键的架构决策是对工具生态进行了整合。系统最初在数据访问、日志和代码系统中使用了 30 多个内部工具,后来经过筛选,精简为一个工具集合,既提升了整体可维护性,也降低了智能体在选择工具时的不确定性。工具层包括受控的 SQL 执行、元数据访问、日志检索系统,以及与基于 Git 工作流的集成。
系统设计也考虑到了安全与治理。SQL 执行由验证层进行约束,敏感数据处理流程包含了检测和缓解暴露风险的机制。此外,所有产生代码变更的增强工作流在部署前均需经过人工审核,确保自动化输出始终处于工程监督之下。
上下文管理是一项重要的技术挑战。多步骤智能体推理需要在交互过程中保持相关状态,同时还要符合词元的使用限制。系统通过结构化上下文压缩与选择性检索策略解决这一问题,让智能体在不突破使用限制的同时保留必要的信息。
这套系统有效减少了工程师处理常规支持任务的时间,同时缩短了各类常见问题的处理周期。目前官方尚未公布具体量化性能数据,但团队表示,工程人力正逐步从被动应急处理转向平台构建与系统改进。
查看英文原文:https://www.infoq.com/news/2026/05/grab-multi-agent-support-system/
本文来源:InfoQ