对话灵感实验室:全帧率 VLM、低成本与分层部署,业务现场不止需要炫技模型
点击查看原文>
作者|陈姚戈
编辑|王一鹏
当多模态大模型成为显学,许多本属于 CV 领域的问题,又被重新摆到了台前。
“大部分现有模型,不管是视频生成模型,还是 VLM,都是先把视频拆成一帧一帧的图片,再用图像编码器编码,最后送进模型。”格灵深瞳旗下灵感实验室 Glint Lab 负责人冯子勇对 InfoQ 表示,“而且这些视频输入都经过抽帧。”
冯子勇所说的“抽帧”,是今天许多视频理解模型默认接受的工程选择。不管是 GPT-4o、Gemini 1.5 Pro 这样的闭源模型,还是 Video-LLaVA、InternVL2、Video-LLaMA 这样的开源模型,很多做法都是按固定间隔抽取帧,或者将长视频切分成数秒级短片段,再送入模型处理。
这么做并不难理解。
一小时视频如果按 24 FPS 计算,就包含近 9 万帧。即使每一帧只产生很少的视觉 token,全帧率输入也会迅速把上下文窗口、显存和推理成本推到难以承受的水平。更何况,视频天然存在大量冗余:相邻帧之间大部分背景、物体和场景并没有变化。把每一帧都完整编码一遍,直觉上就不经济。
因此,过去两年,不少视频编码的研究都在改进抽帧策略。例如从固定间隔采样,走向更智能的关键帧选择。
但在冯子勇看来,只要模型仍然把视频拆成一张张图片来处理,无论抽帧策略如何优化,本质上都没有真正利用视频本身的连续结构。
这条路线可行,但存在巨大浪费。
“图像只是一个瞬间,它前后的连续关系没有在前端建模起来,而是都丢给后端模型去理解。”冯子勇说,“这相当于迫使 LLM,或者中间的模型,去重新理解图和图之间的关系。这不是说不能做,但是很浪费。”
浪费来自两个层面。
第一,算力被浪费了。视频原本就是连续的,相邻帧之间天然存在关系。但在传统流程里,视频先被解码成一张张静态图片,原有的连续结构被打散,模型再用昂贵的计算把这种关系重新学回来。
第二,信息结构被浪费了。视频编码器本身早已在工程世界里存在多年。I 帧、P 帧、运动向量、残差,这些机制原本就是为了描述哪些内容稳定不变,哪些内容发生了变化。视频在被压缩和传输时,已经把很多时空关系显式编码出来了。但今天许多多模态模型的做法,是先把这些结构解开,再让模型重新发现一遍。
面对这些问题,冯子勇认为,可以换一种方式理解视频输入。
“既然视频原来已经有建模好的东西,为什么不直接用这些东西,在上面构建更 compact 的 token,或者更 compact 的表示?让这些本来就存在的信息,直接传给模型。 ”
这种思考萌发于灵感实验室成立之前,并在实验室成立后得以实现。
格灵深瞳一直关注视觉基座和视觉表征能力。出于对模型应用落地的考量,格灵深瞳认为“在后端大模型上堆计算”这件事有持续优化的空间,并且更关心前端视觉编码能否把有效信息提取出来,能否用更少 token 表达更完整的视频内容,能否在效果、成本和部署复杂度之间取得平衡。
2023 年底,随着大模型能力提升、工具链变化,以及客户对多模态能力需求的增加, 格灵深瞳成立灵感实验室 Glint Lab,给予团队更大的研究自主性。 此后,灵感实验室围绕视觉基座和视觉解码框架,先后开源了 RICE-ViT、LLaVA-OneVision-1.5、OneVision-Encoder 等模型。
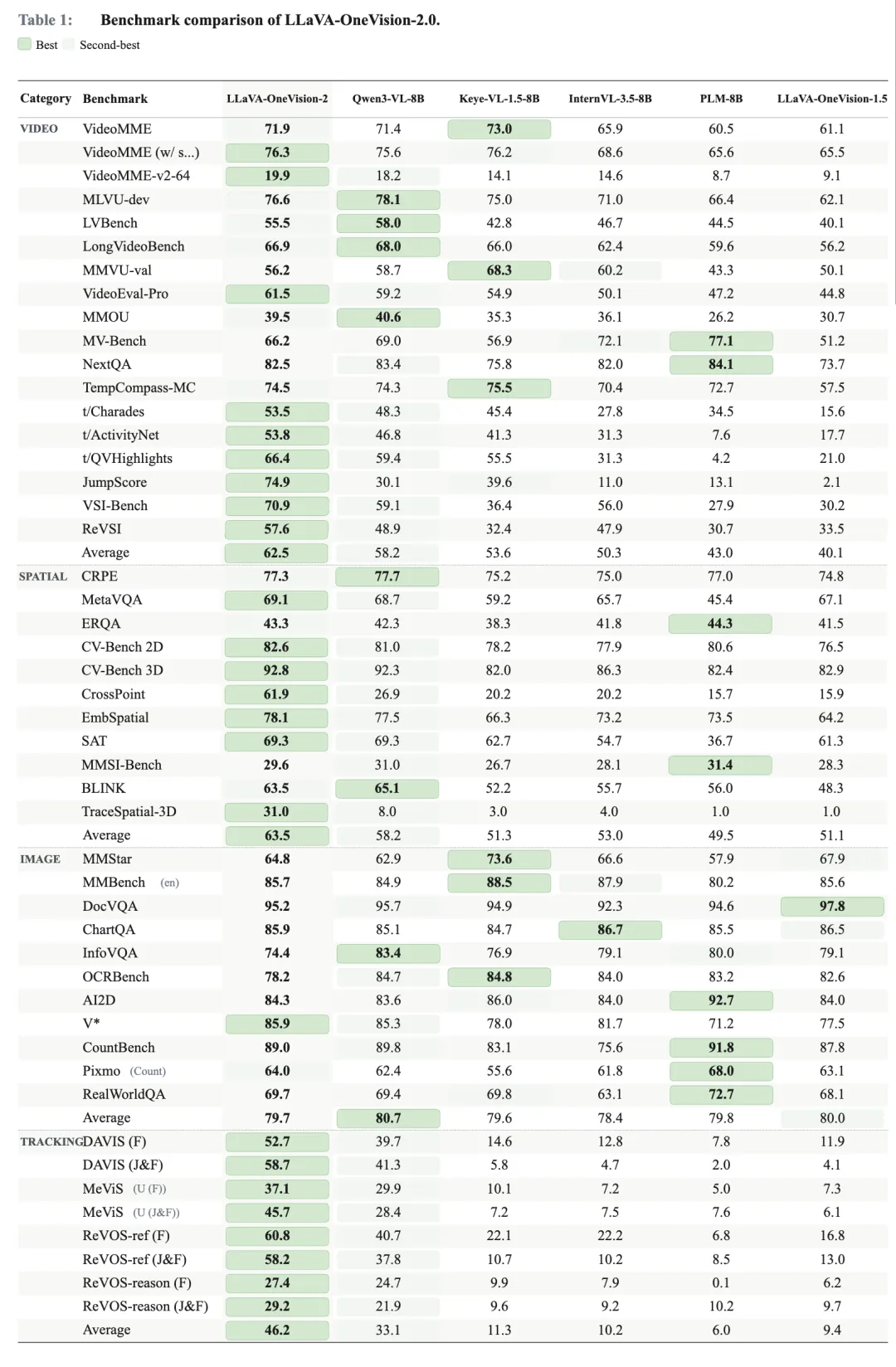
LLaVA-OneVision-2.0 是最新成果。它延续了 LLaVA 系列“视觉基座—projector—LLM”的基本架构,并引入基于 codec 的密集视频输入策略,在保留全帧率感知的同时,降低视频 token 消耗。
LLaVA-OneVision-2.0 的目标,是突破长视频理解中时长、成本和细节的瓶颈。
它通过四阶段渐进式训练,把模型的视频理解能力从 30 秒短片逐步扩展到 10 到 15 分钟长视频,并进化到具备 2D/3D 空间定位和物体追踪的能力。在训练过程中,团队也借助了百度百舸开源的全模态训练框架 LoongForge,为相关训练与迭代提供支撑。
在编码方式上,它采用了 OneVision-Encoder 作为视觉底座。这是一个专门研发的、拥有 24 层结构的 ViT 模型,它负责接收图像或视频输入,通过共享时间、高度和宽度三个维度的位置编码,将其转化为带有语义和时序信息的视觉 token。
OneVision-Encoder 能利用视频 codec 中已经存在的信息结构,保留 I 帧提供的完整空间上下文,P 帧则记录相邻帧之间的运动和残差变化。模型因此可以从 P 帧中提取运动和变化更明显的 patch,不必把每一帧都当成完整图片重新编码。
左图是均匀帧采样(Uniform 128 Frames)
右图是 OneVision-Encoder 基于编解码器选择的图块采样(Codec-Selected Patches)
根据灵感实验室提供的测试结果,LLaVA-OneVision-2.0 在部分视频理解任务上接近 Qwen3-VL 的效果,同时显著降低了 token 成本。
相关链接:
GitHub:https://github.com/EvolvingLMMs-Lab/LLaVA-OneVision-2
模型: https://huggingface.co/lmms-lab-encoder/LLaVA-OneVision-2-8B-Instruct
数据:https://huggingface.co/datasets/mvp-lab/LLaVA-OneVision-2-Data
技术报告:
https://cdn.jsdelivr.net/gh/anxiangsir/ov2_asset@main/LLaVA_OneVision_2.pdf
Blog:https://evolvinglmms-lab.github.io/LLaVA-OneVision-2
此外,对一家以应用见长的 AI 公司来说,多模态模型的价值不能只由参数规模、模型榜单或论文指标定义,它最终要回到客户现场:能不能减少人工配置成本,能不能更快适配新场景,能不能在边缘设备和运营中心之间形成稳定闭环,能不能让模型能力转化为实际业务价值。
因此,格灵深瞳基于模型能力升级打造了新一代视觉 AI 智能产品“视觉智能工坊”。不同于传统“项目制、一次性交付”的视觉算法方案,视觉智能工坊更强调从模型训练、业务编排、边缘部署到运营迭代的全链路打通,将底层多模态能力与具体业务流程衔接起来,帮助客户更快完成场景落地,并在实际运行中持续优化模型效果与应用能力。
在 LLaVA-OneVision-2.0,以及“视觉智能工坊”发布之际,InfoQ 与格灵深瞳灵感实验室 Glint Lab 负责人冯子勇、核心成员谢尹,以及格灵深瞳研发副总裁闫梓祯进行了一次深度交流。
这场交流不局限于技术细节,也包括一家从 CV 时代走来的 AI 公司,如何理解今天的多模态浪潮:有哪些 CV 时代积累的问题意识在 VLM 时代被低估了;为什么一些看起来很先进的研究,如果缺少产品和工程支撑,很难真正落地;以及在成本、效率和效果之间,真实客户究竟愿意为什么样的产品买单。
不过,不论时代怎么变化,格灵深瞳的研究大目标都是不变的,即“从视觉理解世界、理解视觉里蕴含的所有东西。”
以下是 InfoQ 与灵感实验室的对话。
从 CV 到多模态:为什么格灵深瞳还在做视觉基座?
InfoQ:从计算机视觉到多模态大模型,格灵深瞳团队的工作发生了哪些变化?
灵感实验室: 如果只看任务形式,变化很大。过去更多是图片分类、检测、分割和视频结构化等任务;现在可以做视觉问答、视频描述、空间理解,甚至把视频直接输入模型,让模型给出更综合的判断。
但如果看底层问题,变化没有那么大。格灵深瞳早期就在处理图像和视频理解问题,只是过去的方式通常是把视频拆成一帧一帧,对每一帧做检测、分类,再通过大量工程逻辑把结果串起来。现在有了 ViT、LLM 和多模态模型,目标变成让模型直接吃进更完整的视频输入,输出描述、判断或任务结果。工具变了,但核心仍然是理解视觉信息。
我们大的目标都是从视觉理解世界、理解视觉里蕴含的所有东西。
InfoQ:大模型时代,过去 CV 时代的积累还有价值吗?
灵感实验室: 有价值。只是很多问题换了一种说法,被放进了更大的模型框架里。
比如表征学习,以前在 CV 里就是很重要的问题:怎么训练出一个更稳定、更有效的图像表征?怎么让模型真的抓住图像里关键的信息?这些问题到现在并没有消失,只是今天大家讨论时,往往不再单独说“表征学习”,而是把它放进多模态大模型、视频生成模型、生图模型里讨论。
再比如 token 筛选或 token 裁剪,本质上也是老问题。以前做视觉识别时,大家就会关心一张大图里哪些区域是有用的,哪些区域可以忽略。比如识别一个人,天空、墙面、背景可能不是重点,真正有价值的是人、动作、物体这些区域。现在换到多模态模型里,这个问题就变成:视觉 token 那么多,哪些 token 是真正有效的?哪些可以不送进模型?
这些方向以前一直有人研究,但不能说已经被很好地解决了。尤其是现在大家更强调上规模、堆数据、堆模型参数,很多底层细节反而不再被放到第一位。大家更容易说,先把规模推上去,效果上来再说。
但我们不太一样。因为格灵深瞳不只是做研究,也长期做业务落地。业务里最关心的是能不能真正用起来,成本能不能接受,部署能不能稳定。所以我们会更关注这些看起来不那么显眼、但影响真实落地的问题,比如表征质量、token 效率、关键区域选择。
InfoQ:这里说的“表征”具体指什么?
灵感实验室: 简单说,表征就是模型内部用来理解信息的一种表达。
在图像里,表征可以理解为模型把一张图片变成一组特征,用这组特征去表示图片里有什么、哪里重要、不同部分之间是什么关系。在语言模型里也一样。文本本身是离散的 token,每个 token 进入模型前,会先变成 embedding。这个 embedding 也是一种表征。
现在很多模型训练时,更关心最后效果有没有上去,但很少仔细看这些表征在模型内部到底是什么样的:它表达了什么?不同层之间怎么变化?哪些表征真的对任务有帮助?这些问题并不是没人研究,但在当前追求规模和结果的环境里,确实容易被忽略。
我们过去做 CV 会更关注这些问题。比如一个图像特征到底有没有表达出关键视觉信息,它在识别、检索、泛化里是不是真的起作用。现在做多模态模型,我们仍然认为这些问题很重要。
InfoQ:为什么这些问题在今天反而容易被忽略?
灵感实验室: 因为现在模型规模变大了,很多东西被封装得越来越高层。
以前做视觉模型,大家会更关心算子、结构、特征、训练细节。后来框架成熟之后,很多底层工作被 PyTorch、TensorFlow 这类工具包起来了。到了大模型时代,很多团队甚至不再从底层视觉编码器开始做,而是直接拿现成的 CLIP 再接一个语言模型,重点放在数据、指令微调和效果评测上。
这当然是有效的,也让研究和应用推进得更快。但代价是,很多视觉本身的问题被隐藏起来了。比如前端视觉编码是否高效,token 是否冗余,图像和视频里的关键变化是否被准确表达,这些问题如果不解决,后面就只能靠更大的模型和更高的算力去补。
对我们来说,这些不是可以完全跳过的问题。尤其是进入视频理解以后,token 数量、上下文长度、推理成本都会迅速放大。如果前端视觉表征不够高效,后端模型压力会非常大。
InfoQ:视觉编码器和 token 效率会是灵感实验室长期关注的方向吗?
灵感实验室: 会。这一直是我们的主线之一。
我们会继续围绕视觉表征、视觉编码和有效 token 选择去做研究。因为无论是图像理解、视频理解,还是未来和具身智能相关的空间理解,本质上都需要模型用更有效的方式表达视觉信息。
大模型可以带来更强的理解和推理能力,但视觉信息怎么进入模型、哪些信息应该被保留、哪些冗余可以被压缩,这些问题仍然需要在视觉侧解决。对真实业务来说,这不仅影响模型效果,也直接影响成本、延迟和部署可行性。
InfoQ:为什么格灵深瞳要重写视觉基座,而不是直接使用现成的 CLIP 或其他 ViT?
灵感实验室:我们开始做这个方向,大概是在 2021 年 CLIP 出来时。CLIP 给行业带来的冲击很明显。它第一次让很多人看到,视觉和语言可以被放到同一个表示空间里,模型好像一下子具备了跨模态理解和检索的能力。
这对我们也有很大启发。格灵深瞳早期做人脸识别任务,在这个过程中积累了一套相对大规模的视觉训练方法。当时我们在人脸识别上的训练数据已经达到千万级图片。这样的训练规模,在当时已经需要多机多卡支持。
所以当 CLIP 这样新的技术路线出现时,我们会很自然地思考:过去在人脸识别中积累的大规模训练经验,能不能迁移到更通用的视觉表征上?
基于这个判断,我们开始做后来的 MVT 系列。这个方向大概是在 2022 年启动,2023 年形成了第一批研究成果。现在回头看,当时的方法还比较直接,可以说是把已有的大规模视觉训练经验迁移到新的视觉 - 语言表征框架里,但它也构成了后来 OneVision-Encoder 和多模态视觉基座研究的起点。
InfoQ:LLaVA 系列对灵感实验室的启发是什么?
灵感实验室: LLaVA 的启发主要有两点:架构足够简单,训练和数据构造流程相对可复现。相比一些闭源模型,LLaVA 让研究团队更容易理解它为什么有效,也更容易基于它继续扩展能力。
灵感实验室最早做的是视觉基座开源,但视觉基座本身比较偏专业,很难让外界一眼看到特点。后来团队认为,既然已经训练了高质量的视觉编码器,就需要一个视觉解码框架去验证它的能力,LLaVA 自然成为一个合适的选择。
全帧率意味着什么?
InfoQ:为什么“低成本全帧率视频理解”现在还没有被很好解决?
灵感实验室:这其实是业内和业外很大的认知差异。业外可能会觉得,视频理解都发展到今天了,全帧率理解应该已经很成熟了。但从模型底层来看,最大的问题是 token 数量。
视频不是一张图,而是一连串图像。如果一秒钟是 24 帧,就相当于一秒钟有 24 张图片。每一张图片又要被切成很多 patch,再转成视觉 token。哪怕我们用非常激进的压缩方式,比如 48 个像素块对应一个 token,一张较低分辨率的图也可能产生 100 个 token。一秒 24 帧,就是 2400 个 token。
如果一个模型有 100 万 token 的上下文窗口,听起来已经很大了,但如果全部用来放全帧率视频,也就只能容纳大约 7 分钟左右的视频。更何况,模型还要处理文本、指令和其他上下文。所以在真实场景里,比如安防、银行网点、轨交监控,一天 24 小时、多个摄像头的视频,根本不可能全部塞进模型里分析。
人看 7 分钟视频时,会自动忽略大量无关信息。我们知道什么地方该看,什么地方可以跳过。但模型并不会天然知道哪些信息该保留、哪些信息该丢掉。
如果把全帧率视频直接送进去,模型只能把所有帧都编码成 token。这样上下文很快就会被占满。即便是超长上下文模型,也很难真正 work。这就是视频理解和文本理解的差异:文本已经是高度压缩、结构化的信息,而视频的信息密度和冗余都非常高。
InfoQ:为什么抽帧不能彻底解决这个问题?
灵感实验室:抽帧确实是现在最常见、最简单的方法,但它的问题也很明显,它会丢信息。
很多视频任务的关键动作只发生在很短的一瞬间。比如我要找一个人拿起遥控器关电视的那一刻,这个动作可能只持续很短时间。如果我按固定间隔抽帧,就可能刚好没抽到。即使抽到了某一帧,也可能因为缺少前后时序,判断不出这个人在做什么。
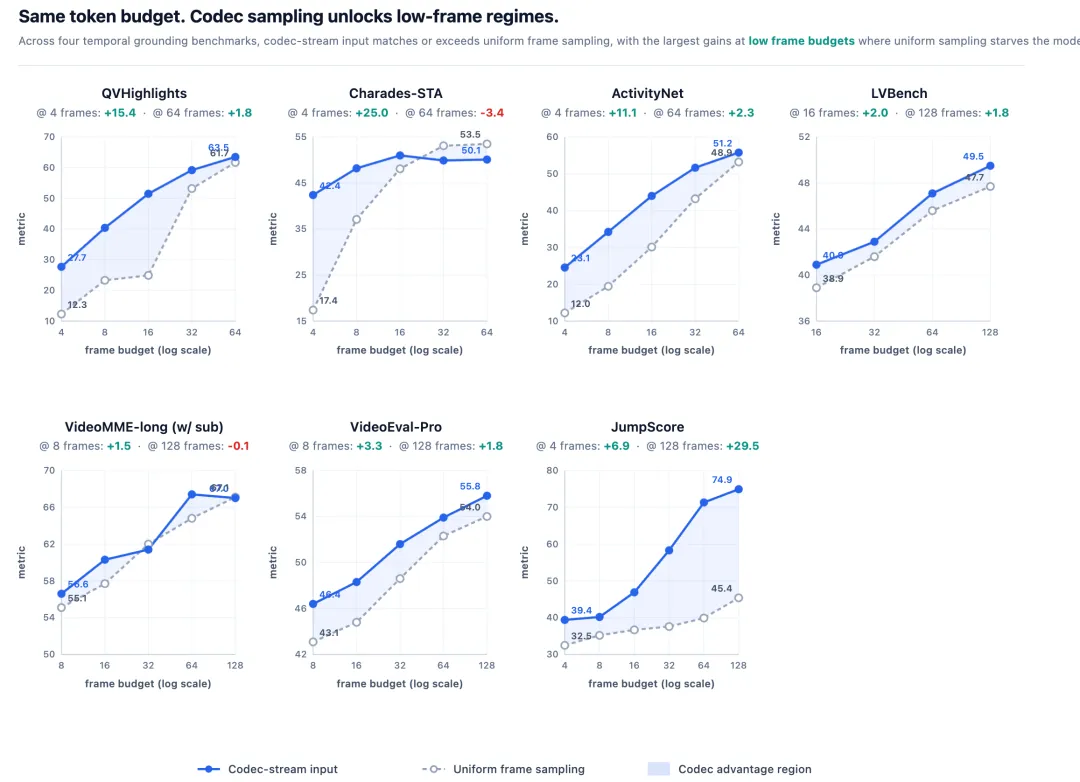
所以全帧率很重要。尤其是做时序定位的时候,比如判断某个事件什么时候开始、什么时候结束,全帧率会更精准。我们现有实验也能看到这个结果。

自左向右分别为:原始视频、均匀帧采样(常规用法)、
运动矢量-残差显著性图、类编解码器风格的块提取
InfoQ:这对视频剪辑 Agent 也会有很大影响。
灵感实验室:是的,现在很多视频剪辑 Agent 表面上是在做剪辑,但底层仍然需要视频理解模型。它需要知道某个事件发生在什么时间点,某个动作从哪里开始、在哪里结束。
如果底层的视频理解模型只能抽帧,它就会丢信息。上层 Agent 系统再怎么优化,也无法弥补底层理解能力的不足。比如它没有办法准确定位一个动作,也就很难做出真正精准的视频剪辑。
这也是为什么 coding agent 现在表现更好,因为代码本质上是文本,而且是高质量文本;但视频 agent 面对的是长视频、密集时序和大量视觉冗余,难度完全不一样。
InfoQ:LLaVA-OneVision-2.0 的基本架构是什么?
灵感实验室: 它仍然延续“视觉编码器 + projector + 大语言模型”的架构。不同之处在于,视觉编码器从面向图像的版本升级为可同时处理图像和视频的 OneVision-Encoder,并引入基于 codec 的密集视频输入策略。
也就是说,语言模型部分并不是这次工作的重点。团队更关心的是,视觉侧能不能在进入语言模型之前,就把视频里的有效信息压缩和组织得更好。
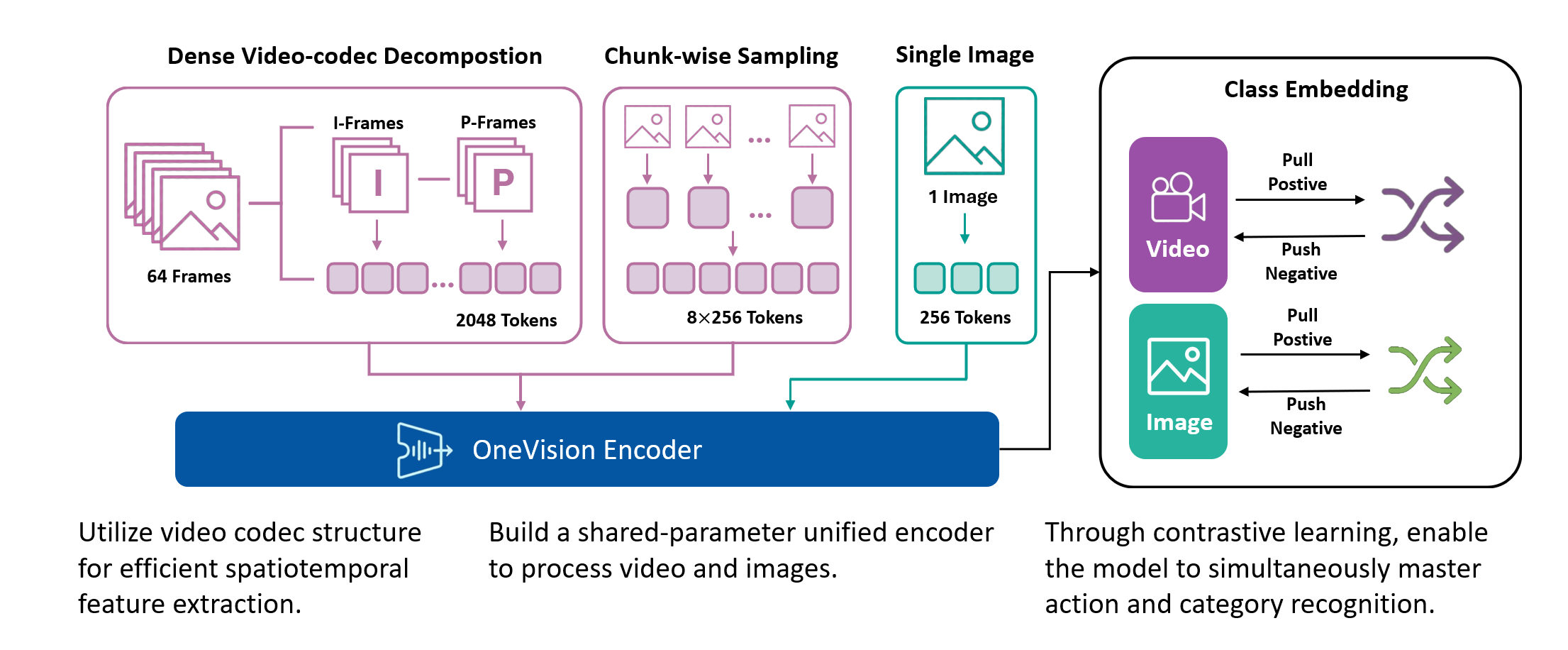
OneVision-Encoder 方法示意图
InfoQ:LLaVA-OneVision-2.0 相比 1.5,主要迭代是在视觉编码器上吗?
灵感实验室:是的,但更准确地说,我们这次主要想解决的是视频理解的问题。我们是从视频任务反推回来的:如果我要让模型更好地理解视频,尤其是高帧率、全帧率视频,核心瓶颈是什么?我认为首先是效率问题,也就是怎么做到低成本全帧率理解。
所以这次我们没有把重点放在语言模型上。语言模型我们直接用了 Qwen。我们真正要做的是往前看,也就是视觉编码器这一层:在视觉输入进入大模型之前,能不能用更高效的方式处理视频信息。
InfoQ:技术报告中提到 LLaVA-OneVision-2.0“只需要约 1/8 的视觉 token”,这个数字怎么理解?
灵感实验室:这个数字主要来自推理阶段的测试结果,不是训练阶段的完整成本测算。它不是一个适用于所有场景的绝对数字,而是在某些测试集上测出来的平均结果。
不同视频的变化程度不一样。有些视频画面变化很多,压缩空间就小一些;有些视频画面变化较少,压缩效果就更明显。平均下来,我们在一些测试场景里能做到大约 1/8 的推理成本。
背后的原理和视频压缩类似。如果两帧画面大部分内容没变,我没有必要把两帧完整保存,也没有必要把两帧完整计算一遍。我只需要记录或计算变化的部分,就能恢复或理解后续画面。
InfoQ:这次工作是否已经解决了低成本全帧率视频理解?
灵感实验室:我不会说我们已经解决了这个问题。更准确地说,我们只是开了一个头。
我们像是打开了一个金矿,但后面还要继续挖。现在的方法肯定还有很多问题,需要继续修 bug、补能力、做优化。我们也看到,行业里其他研究团队开始关注高帧率甚至全帧率视频理解。这个方向会越来越重要。
InfoQ:开源之后,团队收到过哪些反馈?
灵感实验室:我们觉得 LLaVA-OneVision-1.5 是一个非常重要的节点。开源之后,项目获得了很多关注,这也反过来要求我们在后续工作中更加严谨。
比如每次 release 之前,我们都会更认真地复核实验结论、相关论点和表述。因为关注的人多了,我们也希望自己发布的东西不只是“做出来了”,而是真的能对业界相关研究产生启发。
比较惊喜的是,有团队会直接基于我们的数据和训练方向继续做研究。比如 Innovator-VL 项目使用了我们的数据和训练框架,同时加入特定方向的数据,针对某些任务做优化,最后训练出非常 SOTA 的结果。
我们的开源就是为了能够汇聚整个社区的资源,大家一起朝着同一个方向去前进。
视频理解的价值,与灵感实验室的技术“野心”
InfoQ:在视觉理解中,视频意味着什么?
灵感实验室: 我们之所以选择把视频作为一个重要方向,是因为视频很可能会成为未来视觉理解里最核心的形态。图像当然重要,但图像只是一个瞬间;视频不同,它天然包含时间、运动和前后连续关系。
现在很多模型处理视频的方式,仍然是把视频拆成一帧一帧的图片,再用图像编码器编码,最后送进模型。不管是做 VLM,还是做视频生成模型,大部分系统都在沿用类似路径。当然,行业里也有一些改进,但整体上,视频仍然经常被当作一组图片来处理。
我们认为这里面有一个问题:图像和图像之间的连续关系,并没有在前端被建模起来,而是被交给后端模型去理解。也就是说,模型先把视频拆散,再迫使语言模型或中间模块重新理解帧与帧之间的关系。
这并不是说这种方法不可行。它当然可以做,而且已经能做出不错的效果。但我们觉得它很浪费。
浪费主要在于,视频本身就是连续的,前后帧之间天然存在关系。更重要的是,这种关系在视频编码器里早就被建模过了。视频编码技术已经发展了很多年,I 帧、P 帧、运动向量、残差等机制,本来就是为了描述哪些内容稳定不变,哪些内容发生了变化。
但现在很多多模态模型的做法,是先把这些已经存在的结构全部解开,把视频重新变成一帧一帧的图片,再交给模型重新理解一遍。这相当于把原本已经编码好的信息打散,再用更高成本把它学回来。
所以我们的思路是,能不能回到更底层的问题:既然视频里原本就有已经建模好的结构,为什么不直接利用这些结构,在它之上构建更 compact 的 token 或表示?这样一来,本来就存在于视频里的运动、变化和连续关系,就可以更直接地传给模型。
如果这件事能做好,就不仅可以节省算力,也可以节省访存和带宽。理论上,它在效果上不应该变差,甚至有可能更好。因为模型不再需要从一组离散图片里重新推断视频关系,而是可以直接利用视频本身已经存在的信息结构。
InfoQ:灵感实验室如何看待具身智能方向?VLM 是否有机会成为具身大脑 backbone?
灵感实验室: 具身智能会是 AI 的重要应用场景之一,而具身系统天然需要大量视觉任务。现在很多具身模型还处于 demo 阶段,一个重要原因是计算量、功耗、传输和速度还没有解决好。
VLM 如果能够更高效地处理连续视频、空间关系和目标变化,就可能成为具身系统里的主干模型。
InfoQ:除了延续 OneVision-Encoder 的方向继续优化全帧率理解,你们后面还会做什么?
灵感实验室:一个重要方向是流式理解。
现在很多视频理解还是 offline 的:用户把一段视频扔进来,模型分析完再给结果。但真实业务里,很多视频是实时产生的。比如监控、直播、交互式视频系统,都需要模型一帧一帧,或者几帧一个小片段地实时理解。
所以我们后面会尝试流式视频理解。也就是说,模型不是等整个视频结束后再分析,而是在视频不断进入的时候持续理解、持续判断。
另一个更大的方向是理解生成一体。
InfoQ:为什么要考虑“理解生成一体”?
灵感实验室:这个方向有一部分来自技术人的执念。语言模型天然是理解和生成一体的:输入是语言,输出也是语言。但图像和视频不一样。图像理解和图像生成,通常是两套模型;视频理解和视频生成,也往往是两套系统。
所以大家会想,视觉领域能不能也做到理解和生成一体?比如输入一张图,模型不仅能理解它,还能直接生成或编辑图像;输入一段视频,模型不仅能分析它,还能直接做视频编辑。
但这个方向现在还比较早。学术界做得不算多,应用层面也少。我们目前更聚焦的是理解,因为视频理解本身还远远没有被解决。如果理解能力做得足够好,后面的生成、编辑和 Agent 应用都会受益。
理解这件事本身还没有被很好解决。 如果我们现在直接跟进理解生成一体,可能只能做出一个比较中庸的模型,特色不明显。但如果我们把视频理解、图像理解、分割、定位这些基础能力做得更扎实,其他做生成和编辑的人也可以用我们的能力。这样反而更有价值。
理解是底座。只有底座足够好,上层的“生成”和“理解”才能拥有更高的上限。
InfoQ:我在灵感官网发现一个操作体验,可以把某个水果从背景和其他水果里单独分割出来。这个能力看起来很基础,但现在很多 AI 修图产品反而做不好,像分图层、精细分割这样的能力,到了多模态大模型和 AI 修图时代,反而还没有被很好解决?
灵感实验室:我觉得也不能简单说它们做不好。更准确地说,可能技术层面在某个具体的小任务上做得还可以,但到了产品层面,还有很多额外工作要做。不是一个模型做好了,产品就自然解决了。不同产品场景里,可能还有别的需求、别的流程。
但你提到的这个问题,确实对应了一个更底层的问题:从传统 CV 到多模态大模型,有些能力并没有被完全解决。
现在的多模态大模型更偏向语言对齐。也就是说,它更擅长把图像内容转成语言描述,或者围绕图像做问答。但传统 CV 里有很多具体任务,比如检测、分割,这些任务不一定容易被语言表达。
检测还相对容易一些,因为检测结果可以映射成语言或者坐标,比如告诉你某个物体在哪里。但分割更难。分割有明确的像素边界,你很难用语言准确表达“哪些像素属于哪个物体”。
所以,分割不是简单的视觉问答问题。它需要模型理解非常细的边界和区域关系。多模态大模型可能具备一些这方面能力,但不一定特别强。因为如果把检测、分割这类能力强化得太多,模型原本的通用视觉问答能力可能又会下降。
所以现在真正要做检测时,很多人还是会用传统检测器。分割也是类似道理。多模态大模型一路往前走,形成的是一种新的范式,但很多细节能力还没有完全覆盖。这些能力仍然需要更底层的视觉基座继续补上,之后再帮助多模态模型进一步提高。
从技术研究到产品落地
InfoQ:格灵 2026 年推出了新产品“视觉智能工坊”,请为大家简单介绍一下。
灵感实验室:视觉智能工坊不是一个单独的软件或硬件,而是一套软硬一体的视觉智能系统。它有三个子产品:算法训练中心、算法运营中心和边缘哨兵。

边缘哨兵部署在边缘端,接入摄像头,负责实时视频分析和初步感知;算法运营中心负责业务落地,比如复杂业务编排、以文搜图、模型快标快训、项目运营等;算法训练中心则面向算法生产,解决不同场景、不同客户需求下的模型训练和更新问题。
InfoQ:为什么不能把所有视频都上传到云端分析?
灵感实验室: 因为真实场景会受到网络、电力、算力、延迟和成本限制。比如银行网点有大量摄像头,如果所有原始视频都实时上传到私有云或者数据中心,网络带宽和处理延迟都很难满足要求。
边缘哨兵的作用,是先在现场把原始视频解析成结构化信息,筛掉大量无效数据,再把更小、更有价值的信息传给上一级系统。
InfoQ:算法运营中心解决什么问题?
灵感实验室: 算法运营中心主要解决 AI 真实业务落地的问题,一般部署在中心机房里。它会对边缘侧传上来的结果做二次识别和复核,也承担报警管理、模型迭代、业务编排和项目管理等工作。
比如边缘哨兵判断某个人“疑似倒地”,但因为边缘侧算力有限,结果可能不够精准。到了运营中心,可以用更强的算力再判断一次:这个人到底是不是真的倒地,是否需要报警,是否要进入业务流程。
InfoQ:银行场景里,视觉系统主要解决哪些需求?
灵感实验室: 银行场景大致分为两类需求。
一类是安保类需求,比如倒地、尾随、抢劫、异常聚集、危险行为等。这些需求更接近传统安防。
另一类是运营和合规类需求。比如金库取钱时,银行规定必须两个人一起进入。过去这类合规动作主要靠人工抽查监控视频,现在系统可以实时识别,一旦发现只有一个人进入,就自动报警。
所以银行的视觉需求并不只是“看有没有危险”,也包括检查员工是否按流程履职、业务操作是否符合规范。
InfoQ:算法训练中心为什么必要?
灵感实验室: 因为很多视觉算法无法一次训练后到处通用。不同客户、不同地区、不同业务线,对同一个事件的定义可能并不一样。
这些差异会导致同一个算法版本无法适配所有场景,因此需要不断重新训练和调整。但金融、能源、政务等行业的数据往往不能离开客户体系,所以算法训练中心会私有化部署到客户自己的数据中心里,在客户体系内部完成算法生产。
InfoQ:算法训练一开始由谁完成?
灵感实验室: 早期一般由格灵深瞳的算法专家参与。但随着工具越来越完善,客户自己的技术人员、业务人员或运维人员也可以参与训练和调整。
这也是视觉智能工坊希望实现的方向:过去训练一个算法高度依赖算法专家,现在通过工具化和自动化,让客户在自己的体系内也能完成一部分算法生产和迭代。
InfoQ:“一句话生成算法”具体是什么意思?
灵感实验室: 它不是指大模型凭空生成一个可以直接上线的算法,而是把过去复杂的算法生产流程自动串起来。
以前训练一个新算法,可能需要数据工程师、算法工程师、Infra 工程师分别参与,流程包括需求定义、数据准备、数据筛选、数据合成、模型训练、参数调整、部署验证等多个环节。现在格灵深瞳希望把这些能力工具化、skill 化,再由 Agent 统一调度。
用户提出需求后,Agent 可以调用已有的数据检索、数据合成、AutoML、训练和部署工具,自动完成一套算法生产流程。
InfoQ:Agent 在算法生产中具体做什么?
灵感实验室: Agent 更像一个“调度者”。它本身不一定替代每一个专业工具,而是负责调用这些工具,并把流程串起来。
比如算法生产的第一步通常是数据准备。过去数据工程师要根据算法定义,从海量视频中找到相关数据。现在 Agent 可以根据文本需求做跨模态检索,自动筛选相关数据。如果数据不够,还可以调用数据合成工具补齐一部分训练样本。
之后,系统可以基于已有视觉基座和 AutoML 能力完成自动训练和参数选择。这样,算法生产不再完全依赖人工逐步操作。
InfoQ:人还需要参与吗?
灵感实验室: 需要。尤其是在上线部署前,人必须确认结果。
视觉智能工坊可以自动生成算法流程和阶段性结果,但模型仍然可能走偏。对银行、能源、核电、水利、城市治理这类高要求场景来说,最终部署前必须有人审核,确认结果符合业务定义和安全要求。
InfoQ: 客户需求是高度非标的,这时格灵深瞳如何落地?
灵感实验室:格灵深瞳把一个新视觉需求的落地过程拆成三个阶段:冷启动、快速迭代和规模化部署。
第一阶段用多模态大模型解决冷启动。比如客户提出“非法垂钓”识别需求,但现场还没有训练数据。多模态模型可以先根据文字定义和实时视频做判断,让客户先看到效果。
第二阶段用 Glint-MVT 类模型快速迭代。当现场积累了一部分数据后,就可以用更低成本的视觉模型快速调整版本。相比大模型,这类模型的推理成本可以下降大约一个数量级。比如原来需要 2000 张卡的任务,可能降到 200 张卡左右。并且,现在运营中心可以做到分钟级迭代一个版本。
第三阶段用小模型规模化部署。当业务规则稳定、数据积累足够后,就可以训练更小、更便宜、更确定的小模型长期运行。
InfoQ:为什么最终还是要回到小模型?
灵感实验室: 因为大模型成本高。大模型适合解决冷启动和泛化问题,但如果要在几百、几千路摄像头上长期实时运行,成本很难承受。
如果用大模型做实时视频分析,一张算力卡可能只能支撑几路视频;但一个客户现场可能有 2000 个摄像头,如果都使用大模型,成本会非常高。
所以更现实的路径是:先用大模型打开场景,再用中等规模模型快速迭代,最后用小模型规模化部署。大模型负责“从无到有”,小模型负责“长期低成本运行”。
InfoQ:如果小模型效果不够怎么办?
灵感实验室: 可以采用组合式方案。比如小模型先做初筛,把疑似事件筛出来,再交给 Glint-MVT 视觉基础模型或多模态模型做复核。
这样既能控制成本,也能保证复杂场景下的识别精度。格灵深瞳把这类工程化能力放进算法运营中心里,让客户可以根据业务要求配置不同模型之间的协作关系。
InfoQ:随着模型能力的提升,安防和金融这类场景的需求是否变得更加多样?
灵感实验室: 安防、金融等确实是之前视觉 AI 落地做得比较好的场景。
之前主要还是解决一些高频通用的问题,但现在客户的需求开始进入长尾阶段,会提出更细、更碎、更具体的识别需求。过去,为这种低频长尾需求单独训练算法,成本太高。
视觉智能工坊想解决的就是这类长尾算法的快速构建问题。
本文来源:InfoQ