GPT-5.5 登顶时刻,Anthropic 亲口承认 Claude 变笨了!网友群嘲:太敷衍
点击查看原文>
“Claude 变笨了。”
Anthropic 正面回应模型“变笨”:三处优化导致的
过去一段时间,这个声音在 Hacker News、Reddit 以及 X 上此起彼伏。尤其是在万众瞩目的 Opus 4.7 发布后,不少老用户反馈 Claude Code 变得健忘、重复且废话连篇。
作为目前全球最强梯队的编程模型,Claude 的口碑滑坡让 Anthropic 压力倍增。
所以今天一早,Claude Code 研发团队打破沉默,发布了一篇看起来诚意十足的分析文章,名为《An update on recent Claude Code quality reports》,他们在文章中坦言,用户反馈的“降智”并非错觉,而是源于三处看似合理、实则导致连锁反应的产品优化。
没错,Claude Code 真的“变笨”了。
研发团队表示,目前 Anthropic 已修复全部漏洞,并宣布重置所有订阅用户的使用限额以示诚意。
截至 4 月 20 日(版本 v2.1.116),这三个问题均已修复。在这篇文章中,他们详细阐述了发现了什么、修复了什么,以及今后将如何改进,避免类似问题再次发生。
三处优化细节详述
事件的起因,源于产品团队对“用户体验”的过度优化。经过调查,Claude Code 团队找出了三个不同的问题:
第一个优化发生在 3 月 4 日。 通常来说,模型思考时间越长,输出效果越好。当时,不少用户吐槽 Opus 模型思考时间太长,甚至导致 UI 卡死。为了缩短延迟、节省 Token,团队私自将默认推理强度(Reasoning Effort)从“高”降到了“中”。
在产品层面,团队再从中选一个点作为默认值,并通过 Messages API 的 effort 参数传递该值;同时,团队还将其他可选强度通过 /effort 命令提供给用户。
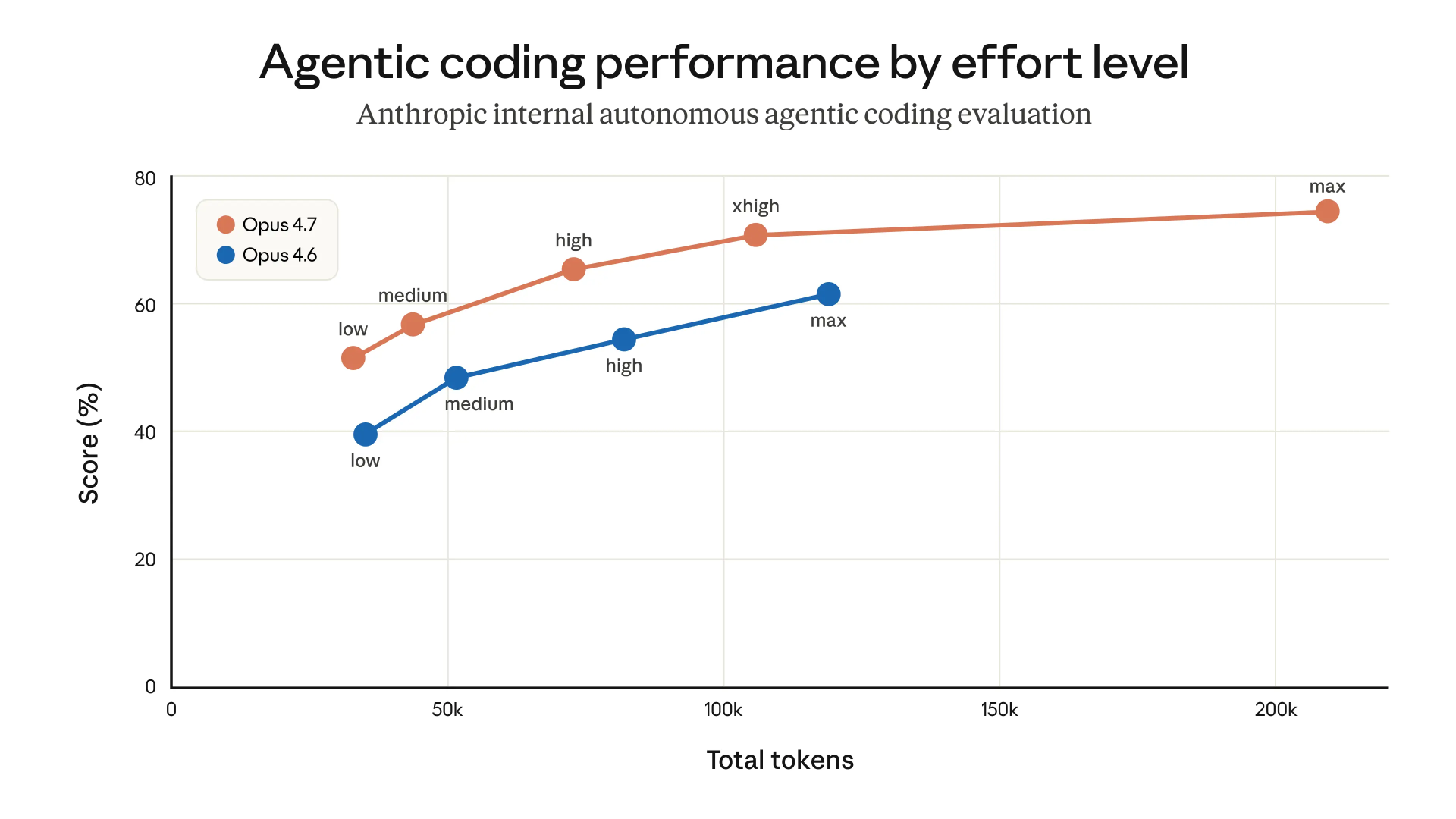
内部评估认为,“中”等强度能以极小的智能损失换取显著的速度提升。然而,真实环境中的开发者并不买账,上线后不久,就有用户反映 Claude Code 感觉变笨了。对 AI 而言,“多思考一秒钟”往往意味着从“生成垃圾代码”到“产出优雅重构”的跨越。
在听取更多客户的反馈后,团队做了多次设计迭代,让当前的推理强度设置更清晰,以便提醒用户可以更改默认值(例如启动时弹出提示、增加内联的强度选择器、恢复“ultrathink”选项),但大多数用户仍然保留了“中”等推理强度默认值。
4 月 7 日,团队在意识到这种取舍逻辑的错误后,将默认强度重新调回了“高”,并在 Opus 4.7 上默认开启了“极高”模式。此问题影响的模型是 Sonnet 4.6 和 Opus 4.6。
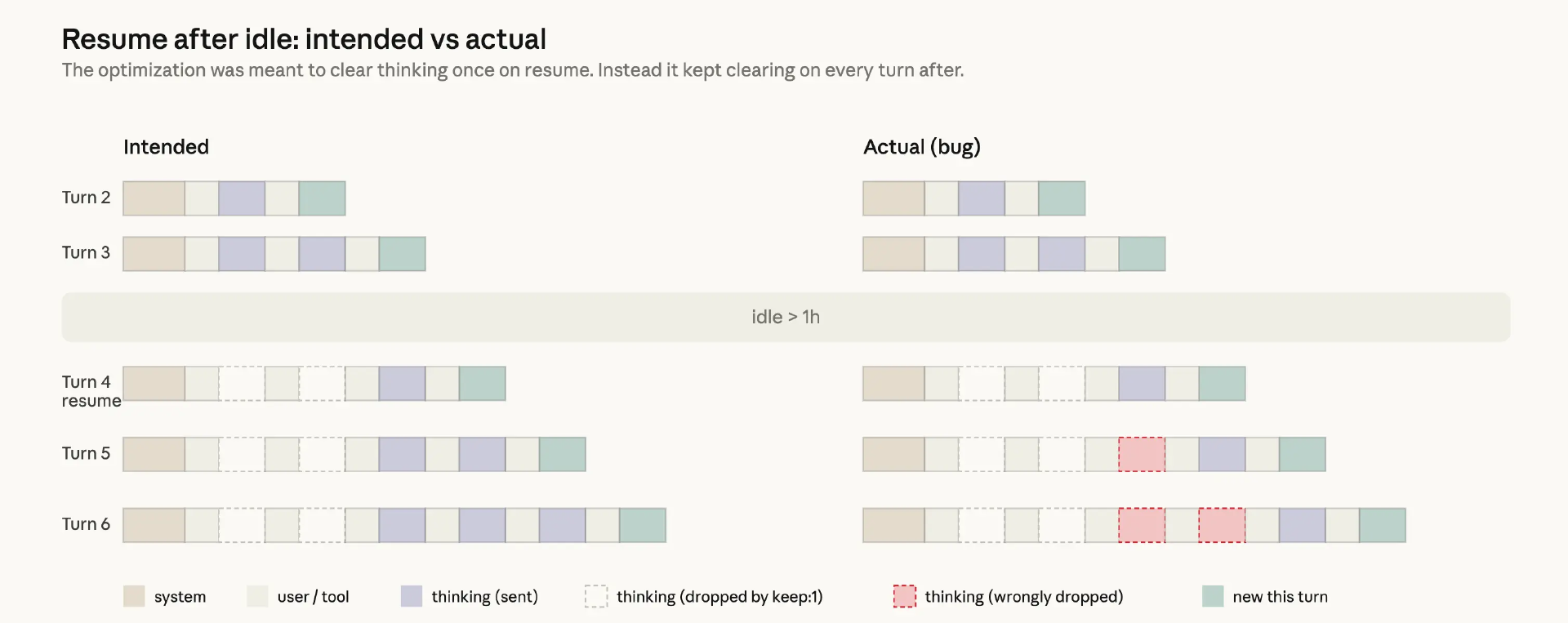
第二个优化发生在 3 月 26 日。当 Claude 执行一项任务并进行推理时,这些推理内容通常会被保留在对话历史中。这样,在后续的每一轮交互中,Claude 都能了解自己之前为何做出某些编辑和工具调用。
3 月 26 日,团队针对这一功能上线了一项本意是提高效率的优化,有点类似于“自动清理历史思考内容”的功能。他们利用提示缓存(prompt caching)来降低用户连续 API 调用的成本并加快速度。Claude 在发起 API 请求时将输入 token 写入缓存;如果一段时间没有活动,该提示就会被从缓存中逐出,为其他提示腾出空间。
原本的设计应该很简单:如果会话空闲超过一小时,系统会剪除旧的推理信息以节省成本。为此,团队使用了 clear_thinking_20251015 这个 API 头部,并配合 keep:1 参数。
但代码中隐藏的一个漏洞:它并没有只清除一次思考历史,而是在会话后续的每一轮中都进行清除。一旦跨过空闲阈值,后续每一轮对话都会触发清理。这意味着 Claude 只能记住最近的一句对话,它彻底忘记了自己当初为什么要修改代码。在用户眼中,Claude 开始重复啰嗦、胡言乱语。这种“健忘”不仅损害了智能,还因为频繁的缓存未命中(Cache Miss)导致用户的使用额度被光速消耗。
据悉,该漏洞的发现过程较为曲折,由于 Anthropic 内部两个互不相关的实验干扰,导致漏洞难以复现——一个是仅用于服务端、涉及消息队列的内部实验,另一个是在思考内容展示方式上的正交改动,该改动在大多数 CLI 会话中掩盖了漏洞,使得外部构建测试时未能发现问题。
此外,该漏洞处于 Claude Code 的上下文管理、Anthropic API 和扩展推理三个模块的交汇点,相关变更已通过多轮人工和自动化代码审查、单元测试、端到端测试、自动化验证及内部试用,且仅在陈旧会话这一边缘情况下出现,因此 Anthropic 花费超过一周时间才找到并确认其根本原因。
值得注意的是,在调查过程中,团队使用 Opus 4.7 对有问题的拉取请求进行了反向的“代码审查”测试。当提供了获取完整上下文所必需的代码仓库后,Opus 4.7 发现了该漏洞,而 Opus 4.6 未能做到。
为防范此类问题再次发生,Anthropic 目前正增加对更多代码仓库作为代码审查上下文的支持,该漏洞也已经在 4 月 10 日 v2.1.101 版本中修复好了。此问题影响的模型是 Sonnet 4.6 和 Opus 4.6。
第三个优化发生在 4 月 16 日。Anthropic 曾为降低 Claude Opus 4.7 版本的冗长程度,修改了系统提示语。据悉,Claude Opus 4.7 相较于前代,明显更加“啰嗦”,虽能在困难问题上表现更出色,但会生成更多输出 token。
在该版本发布前几周,Anthropic 便开始对 Claude Code 进行调整,综合运用模型训练、提示语优化、思考体验改进等多种方式降低冗长程度,其中新增的一条系统提示语——“长度限制:在工具调用之间的文本控制在 25 个单词以内。最终回复控制在 100 个单词以内,除非任务确实需要更多细节”,对 Claude Code 的智能产生了过大影响。
该提示语经过数周内部测试,在 Anthropic 运行的评估集上未出现性能退化,因此于 4 月 16 日随 Opus 4.7 版本一同上线。
但在后续调查过程中,Anthropic 通过更广泛的评估集开展更多消融测试(即从系统提示中逐行删除以理解每行影响),发现 Opus 4.6 和 4.7 版本均出现 3%的性能下降。
为此,Anthropic 在 4 月 20 日的发布中,立即撤销了该条系统提示语。该优化受影响的模型包括 Sonnet 4.6、Opus 4.6 和 Opus 4.7。
未来如何改进?
为了避免再次出现这些问题,Claude Code 团队表示将从下面三个方面进行改进:
首先,是内部全员强制使用公共构建版,确保开发者与用户“同频感同身受”。
Claude Code 团队将推动内部使用版本的统一,确保更大比例的内部员工使用 Claude Code 的精确公共构建版本,而非用于测试新功能的内部版本,以此更贴近普通用户的实际使用场景,提前发现潜在问题。同时,团队将对内部使用的代码审查工具进行改进,并计划将优化后的代码审查工具同步提供给客户,助力客户提升使用体验。
其次,是引入更严苛的提示语审计工具,对系统提示语的每一行修改进行持续的消融测试。
在系统提示语管理方面,Claude Code 团队将增加更严格的控制措施。对于每一次系统提示语的更改,团队都会针对每个模型运行广泛评估,持续开展消融测试以明确每一行提示语的具体影响;同时,已构建新的工具,让提示语的修改更易于审查和审计。
第三,是增加“浸泡期”,对于任何可能牺牲智能换取性能的改动,采取逐步上线的流程。
团队已在自身的 CLAUDE.md 文件中新增指导原则,确保针对特定模型的更改仅限定在该模型范围内,避免跨模型影响。对于任何可能牺牲智能换取其他收益的改动,团队将增加“浸泡期”,扩大评估集范围,并采用逐步上线的流程,以便更早发现并规避问题。
在用户沟通与反馈渠道方面,Claude Code 团队近期已在 X(原 Twitter)平台创建 @ClaudeDevs 账号,用于深入解释产品决策及其背后的原理,同时会在 GitHub 的集中讨论帖中同步相关更新,提升产品决策的透明度。
分析报告没有让用户满意
当 Anthropic 试图用一份详尽的技术报告挽回 Claude 的口碑时,它可能低估了开发者积压已久的怒火。
在官方承认由于“推理强度下调”、“缓存漏洞”和“提示语冗长控制”导致 Claude 性能大幅下滑后,社交媒体上的评论呈现出一边倒的抨击。
对于众多支付高额订阅费的专业开发者来说,这份迟到的“真相”不仅没能平息焦虑,反而因补偿方案的敷衍和官宣时机的微妙被质疑在“作秀”。
在 X 上,一位网友反馈称,即使在重置后,流量消耗速度依然惊人:“我用了 5 个小时,x20 的套餐就烧掉了 64% 的流量,而我什么特别的事都没做。情况正在变得越来越糟。”
还有 X 用户愤怒地表示:“这简直是胡说八道!过去两周,我一直在反思是不是自己的提示词或工作流程出了问题,甚至怀疑过自己都没怀疑过 Claude,结果发现是你们的漏洞吞噬了我的历史记录。把重置当作道歉?这才是真正侮辱人的地方。”
该用户还表示:“过去一年我为 Anthropic Max 支付了约 2400 美元,为 OpenAI 支付了 0 美元。过去 48 小时我切换到 OpenAI 的 Codex 感觉真的非常棒,我正严肃考虑彻底更换系统。失去最忠实用户的方式,不是因为模型出 Bug,而是因为糟糕的道歉。”
另一位网友则精准补刀:“你们总是在每周限额到期前两小时宣布‘重置’,这根本不叫重置,这叫敷衍。”
最令社区玩味的是本次公告发布的时间点——恰逢 OpenAI 发布 GPT-5.5 的当天。有部分 X 用户认为,这样的做法是在分散人们对于 GPT 5.5 发布的关注。
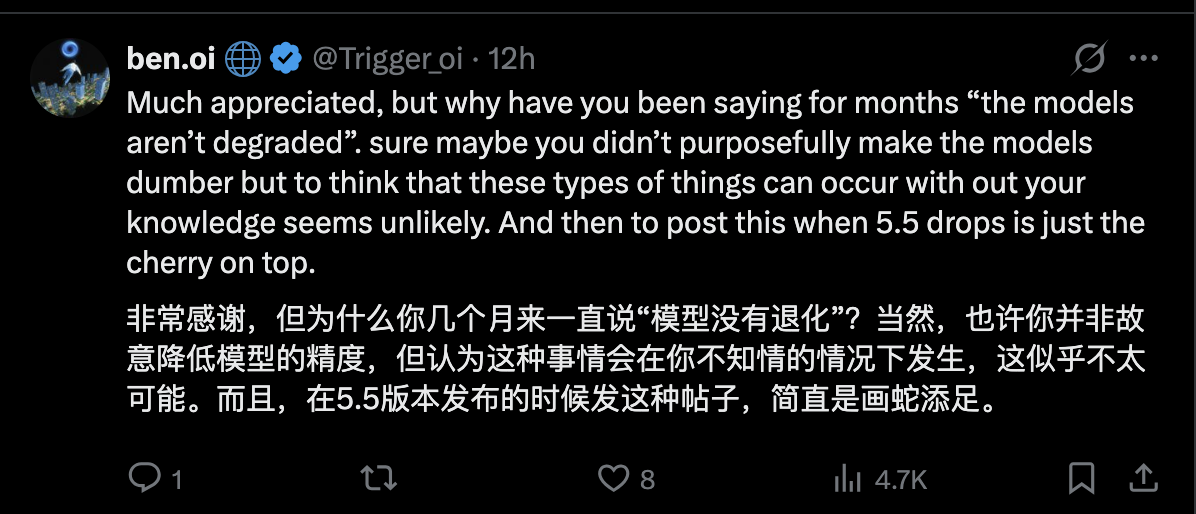
有 X 用户质疑道:“几个月来你们一直坚称‘模型没有退化’,现在却在 GPT-5.5 发布的当天突然官宣漏洞分析,这很难不让人怀疑是在转移注意力。更讽刺的是,你们声称‘用 Claude 开发 Claude’,结果长达 15 天的严重漏洞竟然在内部完全没被发现?”
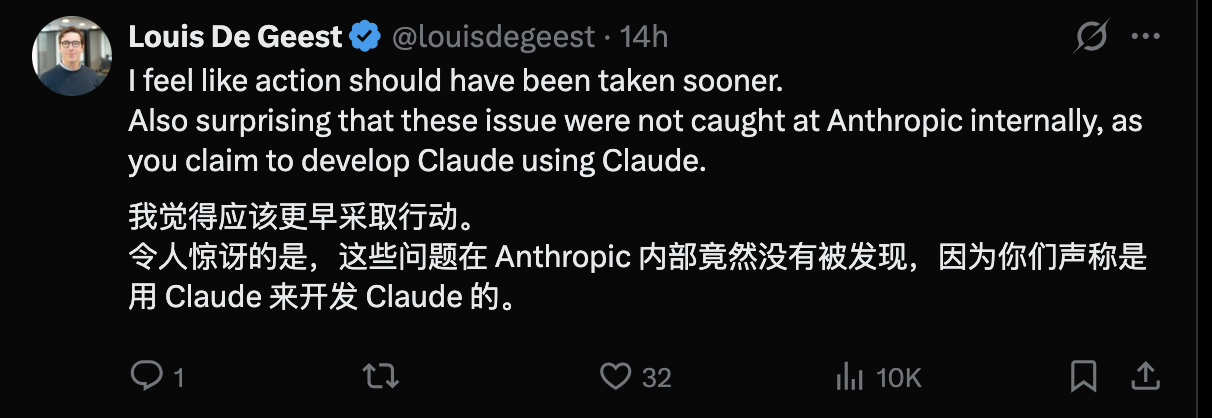
这场风波正在引发连锁反应:核心用户的忠诚度降至冰点。也让一部分人从 Anthropic 转向了 OpenAI。
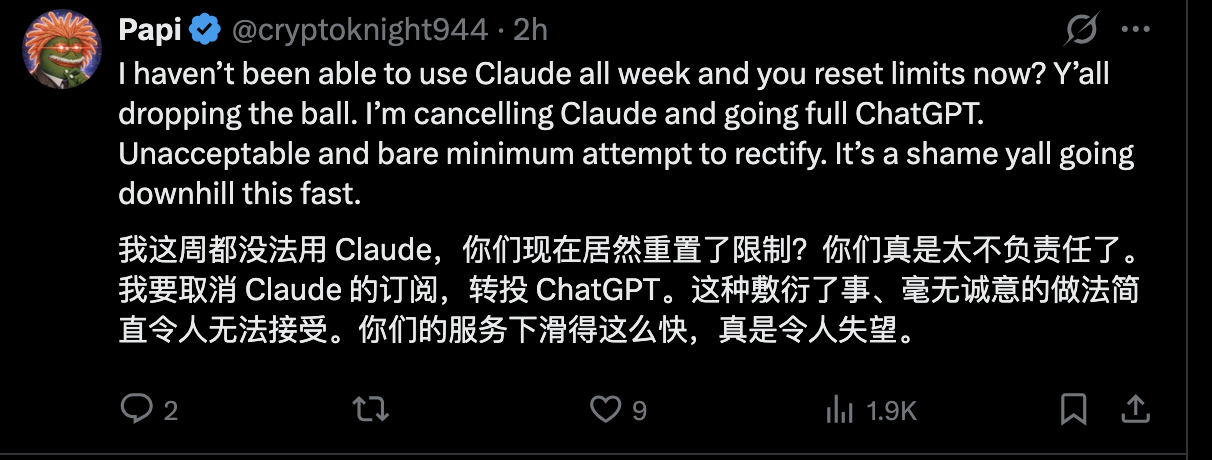
对于 Anthropic 而言,这次危机揭示了一个残酷的现实:在大模型竞争进入白热化的今天,技术领先只是入场券,透明度与对用户时间的尊重才是留住开发者的护城河。

参考链接:
本文来源:InfoQ