GTC 2026发布:矩阵起源 Memoria项目开源——业内首个“Git for Memory” Agent可信记忆框架
点击查看原文>
随着 OpenClaw、Cursor 这样的 AI Agent 大规模走进应用日常,Memory 的管理正成为制约 Agent 走进现实生产力的最后一道枷锁。今天,在 NVIDIA GTC 这一全球 AI 技术大会的舞台上,矩阵起源 CEO 王龙正式宣布开源其核心 Agent Memory 项目:Memoria(https://github.com/matrixorigin/Memoria)。
作为业内首个提出"Git for Memory"概念的 Agent 可信记忆框架,Memoria 不仅仅是让 Agent 记住,更是通过底层 MatrixOne 的 Copy-on-Write 技术,让 AI 记忆变得可回溯、可管理、可信赖。

阶段一:完全没有记忆的 Agent
2026 年,Cursor、Claude Code、Kiro 等 AI 编程助手已经成为数百万开发者的日常工具。它们能理解代码、生成方案、重构架构。但每次你关掉对话窗口,一切归零。下一次对话,它不知道你用什么框架,不知道你的代码风格,不知道上周你们一起做了什么决定。你告诉它二十遍,它明天还会再问。这不是某个产品的 bug。这是整个行业的架构缺陷。
今天绝大多数 AI Agent 本质上是无状态的。每次对话都是一张白纸。Agent 不知道你是谁,不知道你的项目长什么样,不知道你们之前达成过什么共识。它能做的,只是在当前对话窗口里尽可能聪明地回应你。
这意味着什么?
重复沟通成本巨大。 每个新会话都要重新建立上下文。你的偏好、项目约定、技术选型——每次都要重新说一遍,或者靠手动维护的配置文件来补救。
知识无法积累。 Agent 在一次对话中学到的东西,下次全部丢失。上周它帮你重构了 auth 模块,这周它完全不记得。
协作深度受限。 没有记忆的 Agent 永远只能做单次任务执行,无法成为真正理解你项目的长期协作伙伴。
这是今天大多数开发者面对的现实。每一次新对话,都是一次从零开始的关系。
阶段二:Markdown 文件初级记忆
行业并非没有尝试解决这个问题。
.cursorrules、CLAUDE.md、Kiro 的 steering 文件,以及 OpenClaw 这样的社区项目,都在用同一个思路:把 Agent 需要知道的东西写成 Markdown 文件,放在项目里,让 Agent 每次启动时读取。
这比完全没有记忆好得多。至少 Agent 知道你用什么框架、遵循什么代码风格、项目的基本结构是什么。OpenClaw 更进一步,提供了一个社区驱动的规则库,让开发者可以共享和复用这些配置。
但 Markdown 记忆有几个根本性的局限:
静态的。 这些文件本质上是你手动编写的文档。你写一次,很少更新。它们无法自动捕捉开发过程中不断演变的决策——上周二你从 black 换成了 ruff,auth 模块被重构成了 session token,部署脚本在 k8s 迁移后改了。这些变化不会自动反映到你的规则文件里。
单向的。 Agent 只能读取这些文件,不能写入。它无法把对话中学到的新信息持久化下来。今天你告诉它"我们决定用 SQLite 替换 PostgreSQL",明天这个决定就消失了——除非你手动去更新文件。
无结构的。 一个 Markdown 文件里可能混杂着代码风格、架构决策、部署流程、个人偏好。随着项目演进,这个文件会越来越长、越来越难维护,最终变成一个没人愿意更新的屎山。
无法回滚。 如果你更新了规则文件导致 Agent 行为变差,没有简单的方式回到之前的状态。
Markdown 记忆是一个重要的进步,但它本质上是人工维护的静态配置,而不是真正的 Agent 记忆系统。
阶段三:Memoria——让 Agent 拥有真正的记忆
有记忆的 Agent 和没有记忆的 Agent,是两种完全不同的体验。
有记忆的 Agent 知道你喜欢 tabs 而不是 spaces,知道你的项目用 Zustand 的 slice 模式,知道上周你们决定把数据库从 PostgreSQL 切换到 SQLite——不是因为你写在了某个配置文件里,而是因为它在对话中学到了这些,并且自动记住了。
它能基于过去的上下文做出更准确的判断,因为它有历史。它不需要你重复自己,因为它记得。更重要的是,这些记忆是动态的、可管理的、可回滚的。
这就是 Memoria 要做的事。
1、Memoria:让 Agent 的记忆像代码一样可管理
Memoria 是一个开源的 Agent 记忆服务器。它可以无缝接入 Cursor、Claude Code、Kiro 以及各类主流 AI 工具,为 Agent 提供跨会话的持久化记忆。Memoria 也提供了 OpenClaw 插件,可以轻松接入已经在运行的大量龙虾 Agent。
但 Memoria 不只是给 Agent 加了个数据库。
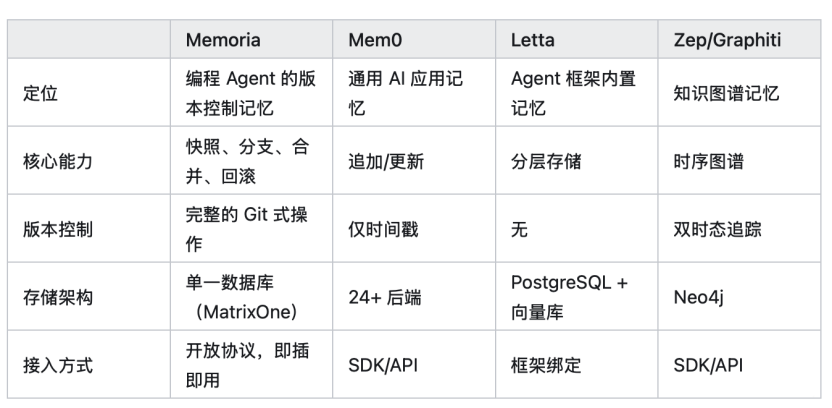
市面上已经有一些 Agent 记忆方案——Mem0、Letta、Zep 等。它们各有所长,但都面临一个共同的局限:记忆一旦写入,就很难安全地管理。
想象一下这个场景:你的 Agent 在过去两周的对话中积累了大量项目记忆。然后你开始一次大规模重构实验,Agent 的记忆也随之更新。实验失败了,你想回到之前的状态——但 Agent 的记忆已经被覆盖了。怎么办?
在传统记忆系统中,你只能手动翻找、逐条删除或修改。这既不安全,也不可靠。
Memoria 的核心创新是:把 Git 的版本控制理念引入 Agent 记忆管理。
就像开发者用 Git 管理代码一样,Memoria 让你可以:
快照(Snapshot):在关键操作前保存记忆状态,随时回滚到任意历史节点;
分支(Branch):在隔离环境中进行实验,不影响主线记忆;
合并(Merge):实验成功后,将分支记忆合并回主线;
差异对比(Diff):合并前预览变更,就像代码的 Pull Request;
回滚(Rollback):出了问题?一键恢复到之前的干净状态。
这不是一个比喻。这是真实的、可操作的版本控制,作用于 Agent 的每一条记忆。
2、为什么版本控制对 Agent 记忆至关重要
这不仅仅是"方便管理"的问题。2025 年的两项重要研究揭示了更深层的原因:
(1)安全性:Agent 记忆可以被悄悄投毒
多篇学术论文(MemoryGraft、MINJA、A-MemGuard)已经证明,攻击者可以通过间接提示注入向 Agent 的长期记忆中植入恶意内容——只需让 Agent 读取一份精心构造的文档。被污染的记忆会跨会话持续存在,逐渐改变 Agent 的行为,而用户可能完全不知情。
大多数记忆系统对此束手无策。Memoria 的快照+回滚机制提供了确定性的恢复路径:发现异常后,直接恢复到最后一个已知的干净状态。
(2)效果:Git 操作显著提升 Agent 能力
Git-Context-Controller 论文(Wu, 2025)表明,将 commit/branch/merge 操作引入 Agent 的上下文管理,使 SWE-Bench 任务解决率提高了 13 个百分点,达到 80.2%。消融实验证实,branch 和 merge 是最后关键提升的来源。具备分支能力的 Agent 自发地发展出了更结构化的探索策略。
Memoria 将同样的原理从临时上下文扩展到持久化记忆——这是一个互补且必要的层。
3、Memoria vs 其他记忆方案:核心差异
4、技术架构

Memoria 的底层由 MatrixOne 数据库驱动——一个同时支持结构化数据、向量搜索和全文搜索的统一数据库。这意味着你不需要拼凑多个基础设施组件,一个数据库解决所有问题。
版本控制能力来自 MatrixOne 的 Copy-on-Write 存储引擎,在数据库层面原生支持零拷贝快照和分支隔离。对包含数千条记忆的空间进行分支操作只需毫秒,且在产生实际变更前不消耗额外存储。
记忆检索采用混合向量+全文搜索策略,按相关性和时效性综合评分。嵌入模型默认本地运行,也支持接入 OpenAI、Ollama 等外部服务。
系统还内置了三个自治理工具,定期自动运行:
记忆治理——隔离低置信度记忆,清理过期数据;
记忆整合——检测矛盾信息,修复数据一致性;
记忆反思——从记忆集群中综合提炼高层洞察。
开源,面向社区
Memoria 现已在 GitHub 全面开源 。只需简单配置,即可为 Cursor、Claude Code、Kiro、OpenClaw 等主流工具装上可信记忆大脑 。
我们希望 Memoria 能够成为 Agent 时代的 Git。代码的变更交由 Git 守护,而 Agent 的认知成长和决策演进,交由 Memoria 承载。
本文来源:InfoQ