Snowflake AI 指南:如何在提升开发效率的同时降低 Token 成本 | 技术实践
点击查看原文>
2026 年,智能体将在企业级应用中取得哪些实质性突破?点击下载《2026 年 AI 与数据发展预测》白皮书,获悉专家一手前瞻,抢先拥抱新的工作方式!
Snowflake 世界中的数据工程正在经历一场重大变化。如今,越来越多的工作不再完全依赖手动完成,而是由 AI 工具辅助推进。这些工具正在出现在各个地方——IDE、命令行,以及 Snowflake 的 Web UI(Snowsight)中。对于今天的 Snowflake 数据工程师来说,工作不再只是移动数据。它更多关乎在 AI 的帮助下,构建可靠、管理良好且成本高效的系统。本文将探讨这种新工作方式的三个主要部分:使用 Cursor 和 GitHub Copilot 进行 Terraform 开发,使用 Cortex Code CLI 打通本地与云端环境,以及使用 Snowflake Cortex UI 直接在 Snowflake 内提升工作效率。
为什么 Snowflake 专业能力比以往任何时候都更加关键
将初级开发者与 Snowflake 专家结合起来,可以形成一个强大的反馈循环,在快速执行与架构完整性之间取得平衡。初级工程师可以使用 AI 快速起草管道或 Snowflake 专用 SQL,而专家则提供必要的治理层,对代码进行审计,确保其符合计算效率、安全数据共享和最佳聚类等最佳实践。这种以指导为核心的审计流程,不仅能捕捉“幻觉”代码或次优查询;它还像一个实时课堂,让初级工程师学习 Snowflake Data Cloud 的细微之处,例如管理 Warehouse credit 消耗以及利用 Dynamic Tables。最终,这种协作确保由初级工程师主导、AI 辅助的开发速度,永远不会以造成臃肿、难以管理或不安全的数据环境为代价。
掌握基础设施即代码:使用 Cursor 和 GitHub Copilot 进行 Terraform 开发
Snowflake 多层架构的管理——包括数据库、warehouse、基于角色的访问控制和网络策略——越来越多地通过 Terraform 完成,以确保可复现性和版本控制。然而,Snowflake Terraform provider 的复杂性,以及 HashiCorp Configuration Language(HCL)固有的冗长性,都会带来显著开销。Cursor 和 GitHub Copilot 等 AI 助手已经成为降低这种复杂性的关键工具,但要有效应用它们,需要对其设置方式以及基础设施任务所需的特定提示工程有细致理解。
架构设置与环境配置
对于数据工程师来说,第一步是根据所需的项目级感知能力选择合适的助手。GitHub Copilot 在行内代码补全和通用 SQL 辅助方面非常有效,但与更集成化的工具相比,它对更广泛工作区上下文的理解可能有限——尤其是在跨多个文件进行复杂 Terraform 重构时。Cursor 是一款基于 VS Code、内置 AI 能力的编辑器,它通过索引代码库并支持跨文件推理,提供更深入的项目感知能力。这使它能够更好地理解关系。
要建立生产级环境,工程师必须安装 HashiCorp Terraform 扩展,并配置 Snowflake provider。项目布局对 AI 效能至关重要;模块化结构允许 AI 解析更小、逻辑上分离的代码块,从而降低上下文窗口耗尽的可能性。
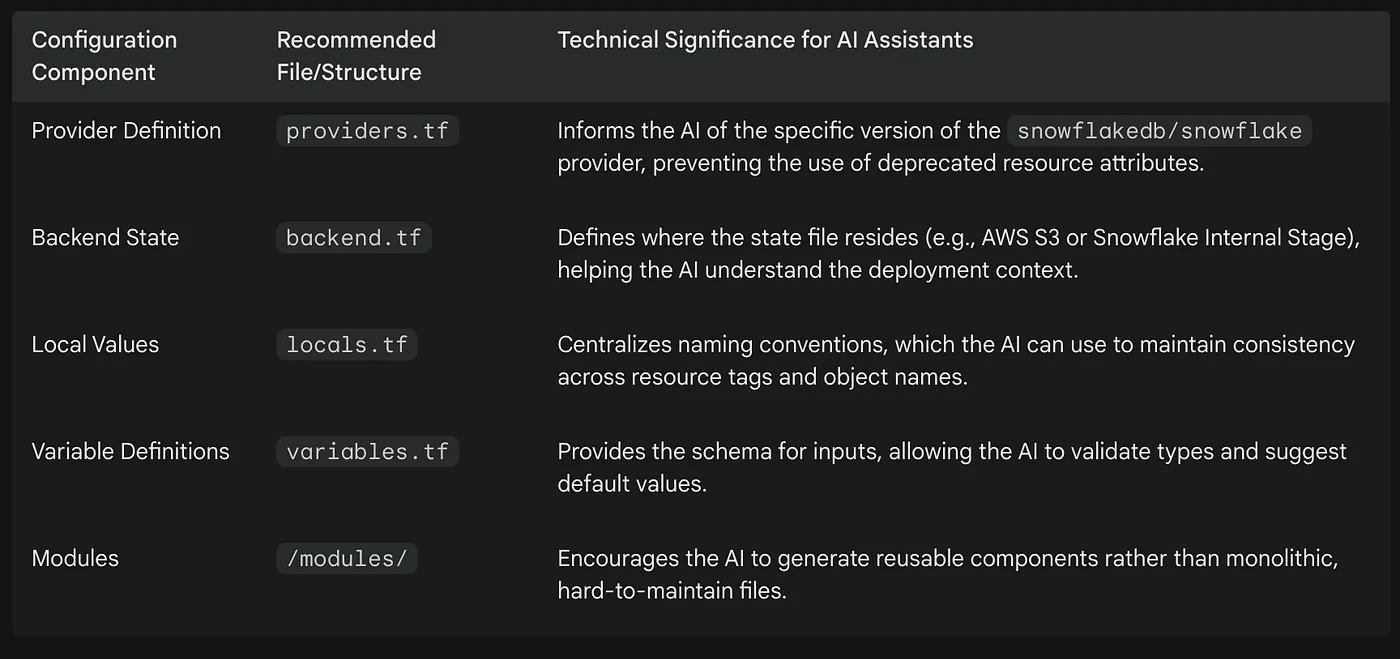
推荐配置
需要注意的一个关键细节是,Snowflake Terraform provider 遵循语义化版本控制,而主要版本发布(例如 2.0.0 及之后版本)对资源 schema 引入了重大破坏性变更。在向 AI 提示之前,确保 providers.tf 中的 required_providers 块被准确定义,是最重要的“须知事项”,因为这可以防止助手生成与旧版、不受支持的 provider 兼容的代码。
面向 Terraform 工作流的高级提示工程
为 Terraform 编写有效提示,与为 Python 或 SQL 编写提示有根本不同。目标通常是转换现有状态,或生成复杂、相互依赖的资源层级结构。数据工程师应避免使用“创建一个 Snowflake 数据库”这类通用提示,而应专注于上下文重构和以安全为中心的模式。
一个高价值工作流是消除硬编码值,也就是“魔法数字”。当工程师发现 CIDR 块、warehouse 大小或保留期限散落在代码各处时,可以通过有针对性的提示来自动完成清理。像这样的提示:“Analyze all .tf files in this workspace. Identify every hard-coded value for warehouse_size, data_retention_time_in_days, and comment. Extract these into variables in variables.tf with appropriate descriptions, and update the original resources to use these variables. Ensure terraform validate would pass after these changes,” 可以利用助手的多文件编辑能力执行全面重构。
通过提示进行安全审计同样重要。数据工程师可以利用 Cursor 的工作区感知能力,扫描权限过于宽泛的 grant。一个有效提示可能是:“Scan our Terraform configurations for any usage of the ACCOUNTADMIN role or any grant that applies ALL PRIVILEGES to the PUBLIC role. Suggest more restrictive alternatives using custom functional roles and generate the necessary snowflake_role and snowflake_grant_privileges_to_role resource blocks”。这种方法通过在误配置真正应用到 Snowflake 环境之前识别它们,将安全“左移”。
对 Terraform plan 的解读,或许是这些助手最复杂的使用方式。大型 plan notoriously 难以手动审查。通过将 plan 输出为 JSON——terraform plan -out=plan.tfplan && terraform show -json plan.tfplan > plan.json——工程师可以将该文件提供给 AI,并使用提示:“Act as a Senior DevOps Engineer. Analyze this plan JSON. List every resource marked for destruction or replacement. For each, identify the specific attribute change triggering the replacement and suggest if a create_before_destroy lifecycle block is necessary to avoid downtime”。
“架构师警告”:谨慎处理
虽然 AI 是一个巨大的力量倍增器,但它不能替代你的工程判断。项目开头的一个“幻觉”提示,可能会把结构性缺陷嵌入到整个代码库中。
在你发布到生产环境之前,请记住以下三条规则:
Experiment First:使用“沙箱”或一个虚拟 Snowflake worksheet 来测试 AI 生成的逻辑,然后再将其集成到主仓库中;
The Human Overlook:永远不要“盲目复制”代码。AI 偶尔可能会建议已弃用的 Snowflake 语法或低效的 join 模式,从而导致你的 credit 消耗飙升;
The Terraform Safety Net:如果你使用 AI 生成 HCL,请务必先运行
terraform plan。确保 AI 没有幻觉出资源删除操作,或者——但愿不会——决定启动一个 4XL Warehouse 来在你的账户里“复制自己”。
信任,但要验证。你的 Snowflake credits(以及你的睡眠时间表)都会感谢你。
用 AI agent 编写优秀的 Terraform 代码,不只是关于第一版草稿;它关乎你的意图与 agent 执行之间反复迭代的“握手”。
一旦你的 AI agent 提供了初始代码块,请按照以下步骤,从“建议的”脚本推进到生产就绪的基础设施:
💡 寻求优化:不要满足于第一版草稿。让 agent 就模块化、变量使用和命名约定提出改进建议,确保代码“干净”且可扩展;
🛡️ 审计安全性与 Bug:明确提示 agent 查找初始生成中可能遗漏的 bug、逻辑错误或安全漏洞——例如权限过于宽泛的安全组。即使在第二次或第三次迭代中,Copilot 仍然可能识别出它此前遗漏的 bug;
📝 自动化文档:通过让 agent 编写完整的 README 文件,并创建解释架构选择和资源依赖关系的设计文档来节省时间;
🤖 强制执行本地标准:切换到 CLI,运行
terraform validate和terraform fmt。这可以确保 AI 生成的代码在语法上正确,并遵循标准 HCL 风格;
🔍 验证意图:设计确定后,运行
terraform plan,并仔细审查输出,确保拟议的基础设施变更与你的预期设计完全一致,然后再执行 apply。
IDE 中的战略性 Token 节省
虽然许多 IDE 助手采用固定月订阅模式,但 Token 效率对于保持低延迟,以及确保模型处在其有效上下文窗口内仍然至关重要。输入上下文中过多的噪声会导致准确性下降。为了节省 Token,工程师应实施若干最佳实践:
第一是使用选择性索引和 .cursorrules。在 Cursor 中,可以定义规则,指示模型忽略大型无关目录,例如 .terraform/ 或大量日志文件。这确保模型的“注意力”纯粹集中在 HCL 源代码上。此外,工程师应使用“选择性上下文”:在发起聊天之前,只高亮相关代码块,而不是每次都发送整个文件。这可以减少 LLM 推理中的 prefill 阶段,也就是模型在生成响应之前处理输入提示的阶段。
另一种节省 Token 的机制是使用本地“记忆”或持久化指令。通过定义全局风格指南,例如“始终使用小写 Snowflake 对象名称”或“资源循环中优先使用 for_each 而不是 count”,工程师无需在每个单独提示中重复这些约束。这会缩短每次交互的长度,并确保模型更频繁地实现“一次成功”。
Cortex Code CLI:改变本地开发体验
Snowflake Cortex Code 命令行界面(CLI)是一种范式转变工具,它弥合了本地终端与 Snowflake AI Data Cloud 之间的差距。不同于执行固定命令的传统 CLI 工具,Cortex Code CLI 充当一个 Agentic shell,能够理解数据工程师的意图、规划多步操作,并与本地文件和云端 Snowflake 对象交互。
安装与多平台支持
Snowflake 最近扩展了 Cortex Code CLI,使其在既有 macOS 和 Linux 支持之外,也支持原生 Windows 环境。对于在多样化技术环境中运行的企业数据团队而言,这一扩展至关重要。
macOS / Linux
curl -LsShttps://ai.snowflake.com/static/cc-scripts/install.sh| sh~/.local/bin/cortex
Windows(原生)
irmhttps://ai.snowflake.com/static/cc-scripts/install.ps1| iex%LOCALAPPDATA%\cortex\cortex.exe
安装之后,首要“须知事项”是它与现有 connections.toml 文件的集成。如果工程师已经在使用标准 Snowflake CLI(snow),Cortex Code CLI 可以无缝继承这些连接定义。这避免了重复凭据管理带来的安全风险。在身份验证方面,CLI 支持面向交互式会话的基于浏览器的 SSO,以及面向需要严格角色绑定场景的 Programmatic Access Tokens(PAT),例如 CI/CD 管道。
与 dbt 和 Apache Airflow 的 Agentic 集成
对于数据工程师来说,Cortex Code CLI 的真正力量在于它对现代数据系统模式的深度理解,尤其是 dbt 和 Apache Airflow。CLI 可以自动完成这些项目的“样板”设置,同时遵循现有连接配置文件,例如 ~/.dbt/profiles.yml。
对于 dbt 开发者,CLI 可用于搭建完整的转换层。像这样的提示:“Explore the raw source tables in the BRONZE schema. Propose and create a set of staging models in dbt that clean and standardize these tables, adding not_null and uniqueness tests to all inferred primary keys,” 允许 CLI 通过 Snowflake SQL 调用执行 schema discovery,然后在本地生成对应的 .sql 和 .yml 文件。这将传统上需要数小时手动完成的任务,压缩成一次具备上下文感知能力的对话。
Airflow 集成同样具有变革性。数据工程工作流经常因为跨工具依赖而失败——例如某个 DAG 任务失败,是因为 Snowflake warehouse 被暂停,或某个 dbt 模型没有填充数据。Cortex Code CLI 可以监控 DAG 健康状态,通过 cortex airflow runs trigger 触发运行,并分析任务日志,以自然语言提供根因分析。它允许工程师提出这样的问题:“Trace the upstream dependencies of the failed daily_sales task and identify if the issue lies in the raw data arrival or a warehouse timeout,” 从而提供数据管道的端到端视图。
运营安全:规划与信任模型
由于 Cortex Code CLI 可以执行 shell 命令并编写 SQL,因此它包含一个基于风险级别的复杂安全架构。这是工程师必须掌握的最关键运营细节,以避免在生产环境中意外执行破坏性操作。
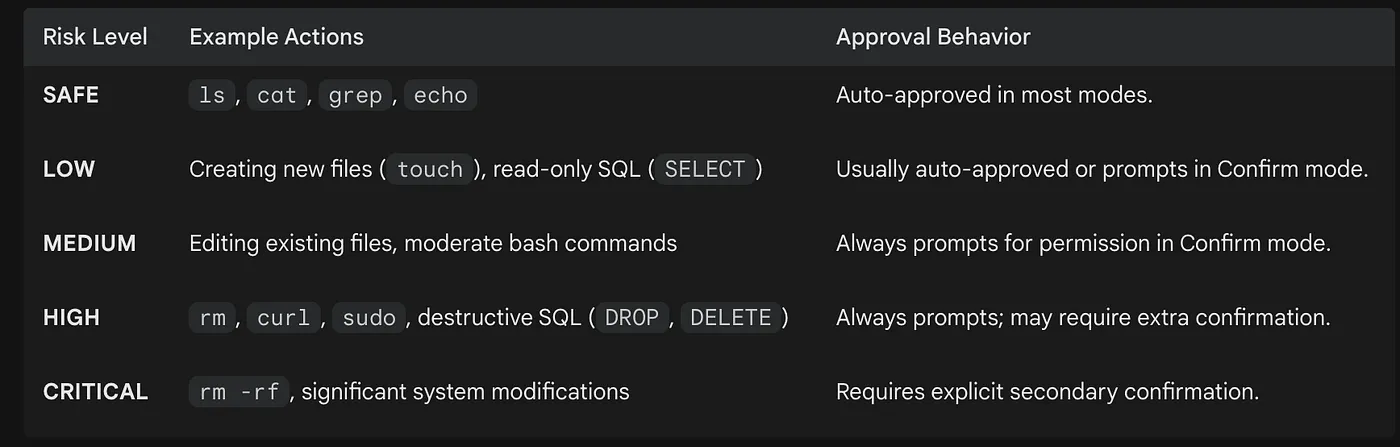
Cortex CLI 的风险
CLI 提供三种交互模式来管理这种风险:Confirm(默认模式,在危险操作前提示)、Plan(通过 /plan 启用,会在采取任何步骤之前显示完整执行序列)以及 Bypass(自动批准所有调用,通常不建议在生产环境中使用)。对于复杂的数据工程任务,从 /plan 开始是一项最佳实践,因为它允许工程师在 AI 修改任何本地文件或 Snowflake 对象之前,先审查其推理。
优化 CLI 中的 Token 使用与性能
CLI 中的 Token 成本由提示的复杂度和长度,以及为任务选择的模型决定。Claude 4.6 和 GPT 5.2 等前沿模型提供最高质量,但会消耗更多 credits。为了最大限度降低支出,工程师应采用以下策略:
战略性会话管理至关重要。CLI 中的每次对话都会自动保存,历史记录会作为上下文传递到后续回合。在长时间运行的会话中,每个回合的输入 Token 会显著增长。使用 /new 为不同任务启动全新会话,或使用 /rewind 回滚到错误转向之前的某个点,可以在一天的工作中节省数千个 Token。
此外,CLI 允许通过 RunSubagent 工具使用 “Subagents”。工程师不必让一个模型在同一上下文中处理研究、编码和测试,而是可以指示 CLI 启动一个特定子 agent——例如用于代码库研究的 Explore——来处理专门的子任务。这种模块化方法可以保持单个上下文窗口精简,并减少与通用规划相关的“Token 膨胀”。
Snowflake Cortex UI:在 Snowsight 中最大化平台内速度
IDE 和 CLI 面向开发者工作流,而直接集成到 Snowsight 界面中的 Snowflake Cortex UI,则旨在与 Snowflake Data Cloud 进行即时、高保真交互。这个持久化 AI 编码 agent 完全感知用户的活动工作区、UI 位置和数据目录,因此它是用于临时 SQL 开发和管理任务的、上下文最丰富的助手。
设置与可访问性功能
在 Snowsight 中访问 Cortex Code 几乎是即时的。它不需要本地安装;工程师只需在 Worksheet 或 Workspace 右下角选择 Cortex Code 图标。最关键的前提条件是分配 SNOWFLAKE.CORTEX_USER 数据库角色,该角色默认授予 PUBLIC 角色,但可能会受到组织策略限制。
Snowsight 中的 Cortex Code 深度集成到 Snowflake Intelligence 的 “agentic” 工作流中。这意味着它不只是建议代码;它使用编排来规划并执行数据探索、PII 识别和成本分析等任务。一个“重要须知”是,Snowflake 最近统一了其 AI 界面,弃用了旧版 Snowflake Copilot,转而采用能力更强的 Cortex Code agent。
加速 SQL 开发与管理工作流
Snowsight 助手擅长将自然语言转换为生产就绪的 SQL,并提供对建议变更的可视化审查。当工程师高亮一段 SQL 并请求优化时,助手会提供 “Diff View”,以便在任何更改应用到 worksheet 之前,清晰比较插入和删除内容。
对于管理任务,助手可以提供此前隐藏在复杂 ACCOUNT_USAGE 查询背后的洞察。工程师可以提示:“Show me a trend of warehouse credit consumption for the MARKETING_WH over the last 30 days and identify any queries that consumed more than 10 credits individually,” 或 “Explain the purpose of the views in the SNOWFLAKE.ACCOUNT_USAGE schema and how they relate to query history”。这种能力将助手转变为一个始终可用的虚拟 “DBA partner”。
数据工程师还可以使用助手生成用于测试的合成数据。像这样的提示:“Create a table named TEST_TRANSACTIONS with 100,000 rows. Include columns for TRANSACTION_ID, AMOUNT, MERCHANT_CATEGORY, and IS_FRAUDULENT. Ensure that ~0.5% of the rows are marked as fraudulent and that their amounts are statistically significantly higher than the average,” 可以在不暴露敏感生产数据的情况下快速创建测试环境。
Snowsight 中的高级提示技巧
为了在 UI 中实现高准确率,工程师必须将模型“锚定”到自己的具体 schema 中。最有效的做法是使用 @ 符号搜索并在提示中包含特定数据库、schema、表或视图。这会为助手提供生成可执行代码所需的精确元数据、列名和数据类型。例如,像 “Query the top 10 customers by revenue using @CUSTOMER_STAGING and @ORDERS_MART” 这样的提示,可以确保模型不会幻觉出对象名称。
此外,助手支持跨会话持久存在的 “Custom Instructions”。这里非常适合存储组织标准,例如“在表定义中始终包含 CREATED_AT 时间戳”或“在复杂 join 中使用 common table expressions(CTEs)以提升可读性”。通过将这些要求移到自定义指令中,工程师可以降低每个提示的复杂度,并确保整个团队的代码质量一致。
在 UI 中节省 Token 并管理 AI 消耗
在 Snowsight 中管理 Token 使用,是提示设计与利用平台内置可观测性功能之间的平衡。与 Cortex Code 助手的每次交互都基于 Token 消耗计费,并通过CORTEX_AI_FUNCTIONS_USAGE_HISTORY 视图进行跟踪。
一种节省 Token 的关键策略是 worksheet 级会话管理。由于每个聊天会话都与特定 worksheet 关联,工程师可以将不同任务拆分到不同 worksheet 中。这可以防止模型不得不处理冗长且无关的历史对话回合,从而尽可能降低输入 Token 数量。此外,如果某个响应不令人满意,使用“thumbs down”按钮可以提供反馈,帮助优化未来生成结果,并可能通过更少回合到达正确解决方案来节省 Token。
工程师还应使用 AI_COUNT_TOKENS 函数对提示进行基准测试。通过测试标准 “staging model” 提示与 “incremental logic” 提示的 Token 数量,团队可以开发只提供必要上下文的“精简”模板。随着组织内 AI 工作负载不断扩展,这种主动式 FinOps 方法至关重要。
AI Data Cloud 中的战略性成本管理与治理
随着组织向 AI 原生数据工程转型,基于 Token 的成本管理和 AI 模型治理成为关键架构问题。Snowflake 引入了技术创新和管理控制,以确保 AI 的采用既具备高性能,又具备财务可持续性。
技术优化:Prefill 与 Decode 阶段
理解 LLM 推理的工作方式,是优化的第一步。推理主要发生在两个阶段:prefill 阶段和 decode 阶段。在 prefill 阶段,系统处理用户输入提示并将其转换为 Token;这正是“提示膨胀”成本最高的地方。在 decode 阶段,模型逐个 Token 生成响应。
Snowflake 的 SwiftKV 技术专门优化 prefill 阶段。通过复用早期 transformer 层的“隐藏状态”,为后续层生成 KV(Key-Value)缓存,SwiftKV 消除了冗余计算。对于数据工程师来说,这意味着 Llama 3.3 和 Llama 3.1-405B 等模型可以处理大型上下文窗口——例如向 AI 提供庞大的 DDL schema——同时推理成本最高可降低 75%,并使 “time to first token” 加快 50%。
通过 Account Usage 视图实现可观测性与 FinOps
为了管理 AI 支出的“不可预测”性质,Snowflake 通过 Account Usage 视图提供全面遥测。这些视图将使用数据聚合到一小时窗口中,使工程师能够按模型、用户和查询跟踪消耗。
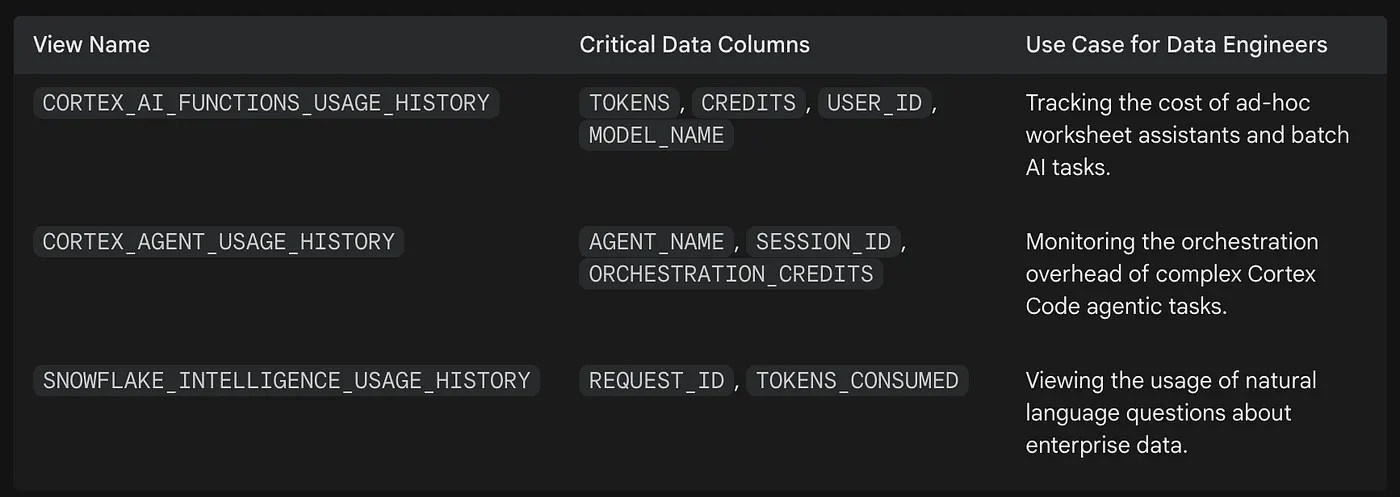
跟踪 AI 成本
工程师可以通过查询这些视图,使用 Streamlit in Snowflake(SiS)构建交互式监控仪表板。仪表板可以可视化输入与输出 Token 之间的比例,帮助团队识别提示是否过于冗长(高输入),或模型是否被要求生成过长响应(高输出)。这种粒度对于 chargeback 报告和容量规划至关重要。
实施按用户和按账户的支出限制
为防止未优化提示或失控查询导致“预算危机”,管理员可以实施多层级成本控制。Snowflake 允许在账户和单个用户级别配置每日 credit 限制。
-- Set an account-wide daily limit of 20 credits for the Cortex Code CLIALTER ACCOUNT SET CORTEX_CODE_CLI_DAILY_EST_CREDIT_LIMIT_PER_USER = 20;-- Set a per-user override for a lead data engineer needing more capacityALTER USER senior_engineer SET CORTEX_CODE_CLI_DAILY_EST_CREDIT_LIMIT_PER_USER = 50;-- Block your boss's access to the CLI while allowing Snowsight accessALTER USER boss SET CORTEX_CODE_CLI_DAILY_EST_CREDIT_LIMIT_PER_USER = 0;ALTER USER senior_analyst SET CORTEX_CODE_SNOWSIGHT_DAILY_EST_CREDIT_LIMIT_PER_USER;
当用户达到其每日限制时,对该特定使用界面(CLI 或 Snowsight)的访问将在滚动 24 小时窗口内被阻止。对于更高层级的控制,工程师可以实施自动告警。可以配置一个每小时运行的 task,检查 CORTEX_AI_FUNCTIONS_USAGE_HISTORY,并在账户总支出超过月度阈值(例如 1000 credits)时发送电子邮件通知。
治理与安全最佳实践
AI Data Cloud 中最重要的安全原则,是遵循 Role-Based Access Control(RBAC)。Cortex Code 及相关 CLI 工具会遵守当前活动 Snowflake 角色的权限。数据工程师绝不应使用 ACCOUNTADMIN 角色进行日常开发;相反,他们应使用 DEVELOPER_ROLE 或 ANALYST_ROLE 等功能角色,确保 AI 只能访问当前任务所需的数据。
在托管型企业环境中,组织可以向用户工作站部署系统级 managed-settings.json 文件。该文件可以强制执行单个用户无法覆盖的策略,例如将工具访问限制在某个模式 “allowlist” 中、强制最低 CLI 版本,或完全禁用 “Bypass” 模式。这确保即使单个工程师使用 AI 加速工作,组织仍能保持一致且安全的运营姿态。
结论:编排数据工程的未来
Cursor、Cortex Code CLI 和 Snowflake Cortex UI 的集成,不仅仅代表一组生产力工具;它标志着数据工程实践方式的根本转变。通过从手动编码模式转向智能编排模式,工程师可以弥合复杂基础设施需求与快速数据交付需求之间的差距。无论是通过 Cursor 面向 Terraform 的多文件重构能力、Cortex Code CLI 提供的无缝本地到云端桥接,还是 Snowsight 助手具备上下文感知能力的高速度,AI 增强型工程师都能够构建更具韧性、治理更完善且成本更高效的系统。
在这个新时代取得成功,需要秉持 “FinOps for AI” 思维——主动管理 Token 消耗、利用技术优化,并通过 RBAC 和托管设置实施强健治理。随着 Snowflake 持续演进为一个“Snowflake 专业能力成为始终在线能力”的平台,数据工程师的角色将越来越聚焦于对这些 Agentic 系统进行战略性编排,以大规模交付可信的企业智能。
更多
如需持续了解更多 Snowflake 相关文章,请在我的 Medium 主页关注我:Eylon’s Snowflake Articles。
我是 Eylon Steiner,Infostrux Solutions 工程经理,也是 Snowflake Data Superhero。你可以在 LinkedIn 上关注我。
订阅 Infostrux Medium Blog:https://blog.infostrux.com,获取最有趣的数据工程和 Snowflake 新闻。通过 GitHub 关注 Infostrux 的开源工作。
点击链接立即报名注册:Ascent - Snowflake Platform Training - China,更多 Snowflake 精彩活动请关注专区。
本文来源:InfoQ