Uber Hive联邦架构:1.6万数据集、10PB数据去中心化,支撑大规模分析零停机
点击查看原文>
Uber 对其 Hive 数据仓库进行了重新设计,将超过 16000 个数据集(总量超 10 PB)实现去中心化部署,以此解决可扩展性、运维及安全方面的挑战。此前,所有配送业务数据集都集中在单一 Hive 实例的同一命名空间下,存在级联故障、资源争抢与治理瓶颈等风险。通过对 Hive 数据库进行联邦化改造,Uber 得以保障服务高可用、落实最小权限访问控制,同时支持各领域数据集独立扩容,为业务团队赋予运维自主权。
此次迁移采用了基于指针的方案,利用 Hive Metastore 将数据集重定向到新的 HDFS 路径,无需复制 PB 级数据。每个数据集仅需复制一次到去中心化目标位置,随后更新原始指针,确保迁移过程中查询可正常执行。
Uber 工程师 Vijayant Soni 解释道:
在 HMS 中更新数据集指针为瞬时操作,可保障核心工作负载持续运行。该方案确保依赖 Hive 的分析任务与机器学习管道实现零停机。
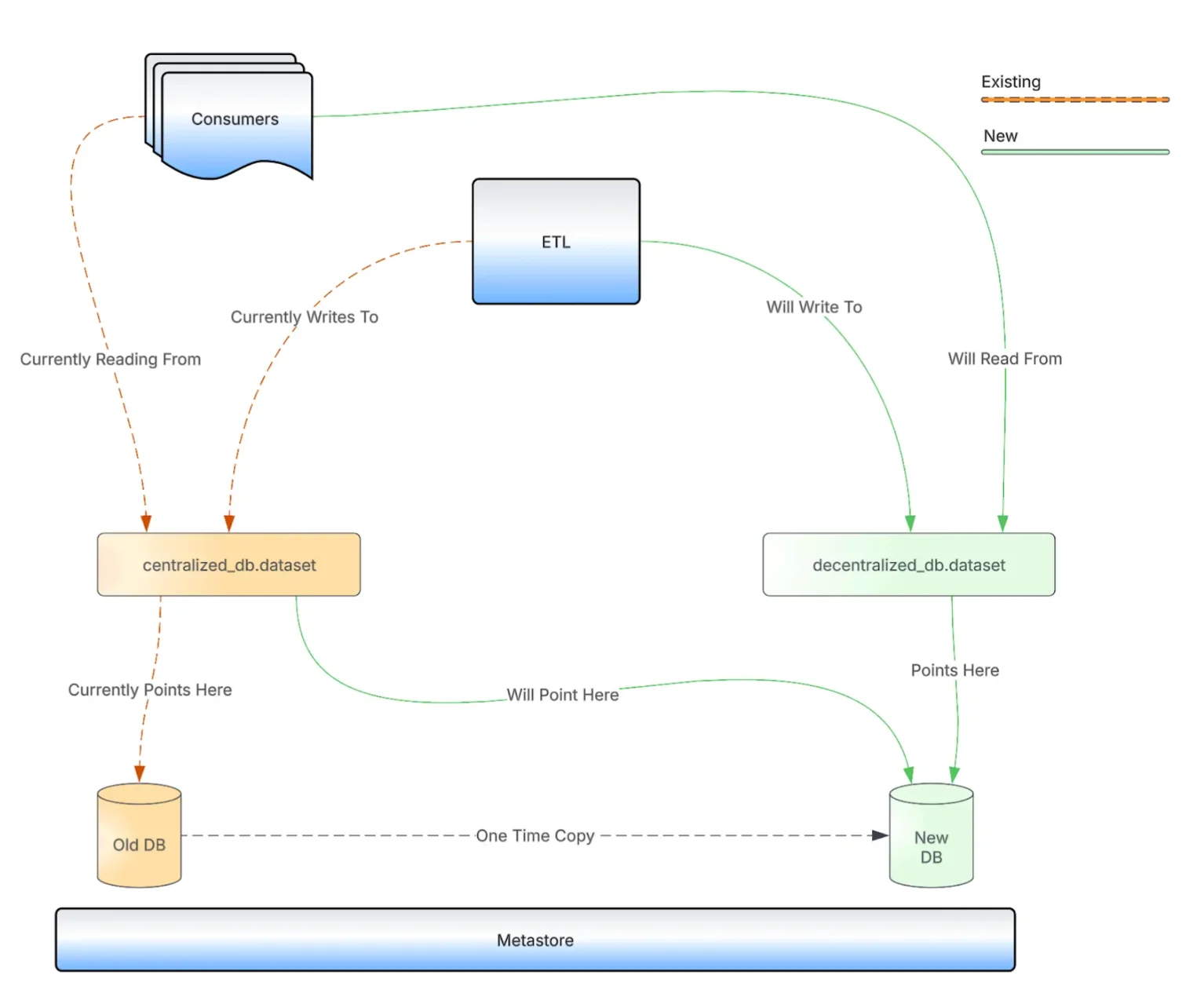
基于指针的 Hive 数据集迁移示意图,展示新旧 HDFS 路径对比(来源:Uber 博客文章)
支撑本次迁移的系统包含四大核心组件:引导迁移器(Bootstrap Migrator)、实时同步器(Realtime Synchronizer)、批量同步器(Batch Synchronizer)及恢复编排器(Recovery Orchestrator)。引导迁移器负责数据集的初始迁移,通过分布式 Spark 作业与校验和验证保障数据完整性。实时同步器与批量同步器在迁移过程中维持源端与目标端的元数据一致性,支持双向更新,期间团队可正常读写数据。恢复编排器会对指针备份进行追踪,在检测到不一致时可安全回滚。这套人机协同验证与自动化检查机制,让团队能够稳妥推进迁移,同时降低运营风险。
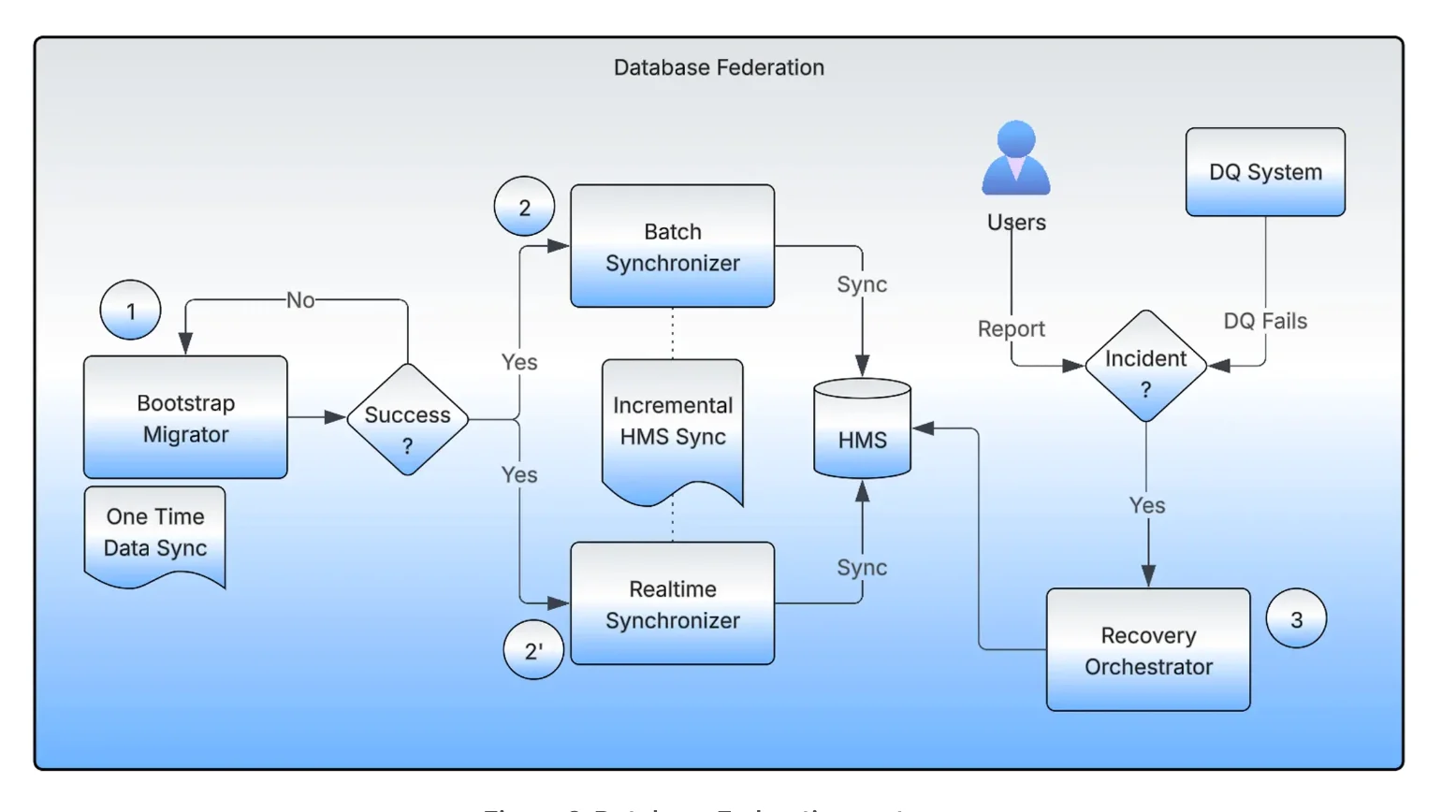
数据库联邦系统架构图(来源:Uber 博客文章)
Uber 的去中心化架构解决了原有单体模式的诸多局限。在旧系统中,多个团队争抢相同的计算与存储资源,产生“吵闹邻居”效应,可能导致核心工作负载运行变慢。过宽的 ACL 权限扩大了配置错误的影响范围,而集中式治理则拖慢了更新速度并形成瓶颈。通过对 Hive 数据库去中心化,并在领域级别实施严格的 ACL 管控,各团队获得了数据集所有权,提升了可观测性、合规性与工作流效率。
此次迁移还通过减少冗余数据集副本降低了存储开销,简化了新数据集的接入流程。包含迁移前检查与审计日志在内的自动化流程在保障数据完整性的同时满足了监管合规要求。工程师可通过仪表盘监控迁移进度,追踪数据集状态、指针更新及同步指标,提升了过程透明度与运营信心。整个迁移过程中,数千个数据集完成迁移,累计执行超 700 万次 HMS 同步,并通过清理陈旧数据集回收了超过 1 PB 的 HDFS 存储空间。
该方案支持持续扩展,可确保新增数据集不会对现有工作负载造成中断。通过将责任分散至各个团队,Uber 减少了对中央运营团队的依赖,缩短了反馈周期,并提升了分析生态系统的弹性。
【声明:本文由 InfoQ 翻译,未经许可禁止转载。】
查看英文原文:https://www.infoq.com/news/2026/04/uber-hive-decentralized-data/
本文来源:InfoQ