Uber 推出流式优先数据湖 IngestionNext ,将延迟和计算量降低 25%
点击查看原文>
Uber 工程师对公司数据湖摄入平台的架构进行了重构,从计划批处理作业转向了一个流式优先系统。该平台名为 IngestionNext,可以持续处理事件流,将摄入延迟从小时级降低到分钟级,加快了分析和机器学习工作负载所需数据的准备速度。
此前,摄入管道依赖于 Apache Spark,并以计划批处理作业的形式运行。虽然能够进行大规模处理,但批处理管道延长了数据分析和实验用数据的就绪时间。
在 LinkedIn 上, Kai Waehner(Global Field CTO)在一篇博文中提到:
这一举措的核心在于将数据新鲜度视为数据质量的关键维度。
IngestionNext 引入了流式优先管道,在将事件提交到数据湖之前持续地处理事件流。事件通过 Apache Kafka 流动,由 Flink 作业处理,然后写入 Hudi 表,支持事务性提交、回滚和时间回溯。新鲜度和完整性会进行端到端的测量。
该架构支持数千个数据集和海量的全球数据量,使分析仪表板、实验平台和机器学习模型能够更快地获得所需的数据。控制平面自动化作业生命周期、配置和健康监控等任务,而区域故障转移和回退策略则用于保持连续性并防止中断期间丢失数据。
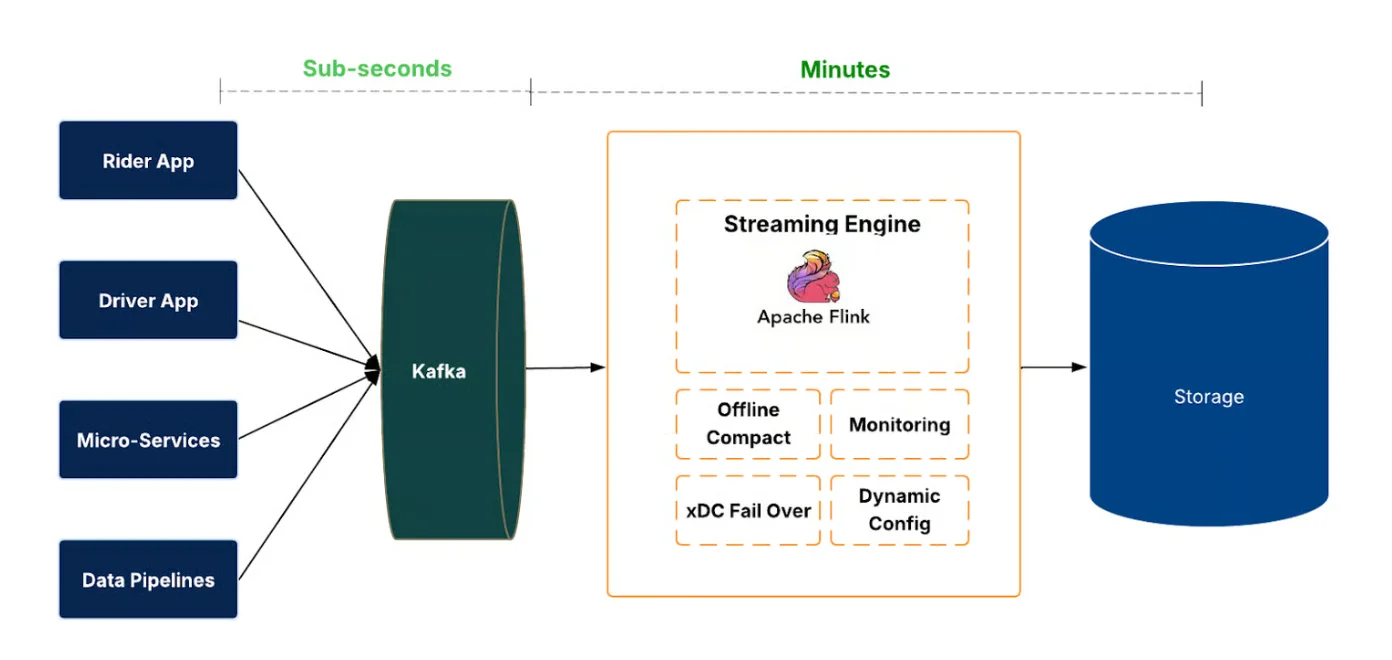
IngestionNext 架构(图片来源:Uber 博客)
转向流式摄入模式带来了几个技术挑战。其中一个挑战是要在数据湖中创建许多小文件,这会降低查询性能和存储效率。为了解决这个问题,工程师实现了 Parquet 文件的行组级合并策略,并添加了压缩机制,从而在持续数据摄入期间保持高效的文件布局。包括 Apache Hudi 在内的开源工作探索了使用填充和掩码来对齐不同的模式,从而实现支持模式演变的合并,不过这增加了实现复杂性和维护开销。
团队还在分布式流处理管道中实现了检查点、分区倾斜以及恢复机制。系统会跟踪从上游数据流的偏移量,并协调提交过程,确保摄入作业能够保持数据正确性,并能够在发生故障时可靠地恢复。
据工程师称,转向流式摄入还提高了资源效率。通过使用持续运行的流式作业(随传入数据量扩展)取代计划批处理工作负载,该系统将计算使用量减少了约 25%。
在 LinkedIn 上一篇博文中,Uber 工程博客合作编辑 Suqiang Song 提到:
这实现了一个从摄入到转换再到分析的完整的端到端实时数据栈。
虽然新的摄入平台提高了进入数据湖的原始数据的新鲜度,但工程师也承认,下游转换和分析管道可能仍会引入额外的延迟。未来的工作将集中在将流式能力扩展到数据处理栈,以确保新鲜度改进能够传播到整个分析工作流中。
声明:本文为 InfoQ 翻译,未经许可禁止转载。
原文链接:https://www.infoq.com/news/2026/03/uber-streaming-date-lake/
本文来源:InfoQ