“为了让工程师用 AI,公司会裁掉一半人!”硅谷顶级大佬直言,AI 一天 3 小时搞定工作,还搞 996 的公司必垮
点击查看原文>
AI 正在把软件行业推入一种很矛盾的状态:一边是前所未有的兴奋感,另一边却是越来越强的疲惫感。Steve Yegge 把这种状态叫作“吸血鬼效应”,即 AI 会让人异常亢奋,忍不住一路干下去,创业者和工程师白天困到打盹,晚上却还在被新想法和新工具推着往前冲。
作为一位做了 40 年软件工程的老兵,他曾长期在 Amazon 和 Google 工作,以犀利、敢说、而且屡屡说中的行业判断闻名。他在最新的播客节目中直言,企业正在默认裁掉约 50%的工程师,只为供养剩下的人全力使用 AI。如今还停留在传统 IDE、只把 AI 当辅助工具的工程师,很快会被批量淘汰,因为 AI 的本质不是替代人,而是百倍放大人的能力,让小团队足以碾压臃肿的大公司。
他一针见血地指出,移动与云之后,软件行业早已创新停滞,大公司的创新已经名存实亡。他对比了 Anthropic 和 Google 来证明公司文化对创新的影响。AI 带来的百倍提效下,人一天真正高效的工作时间只有 3 小时,继续强行 996 只会榨干员工、拖垮公司。
他预测,未来的开发范式将彻底重构,编程不再是敲代码,而是对着可视化的 AI 形象对话、指挥 Agent 去干活,Gas Town 这样的实验已经证明,AI 指挥 AI 才是下一代主流模式。他告诫所有人,不要试图比 AI 更聪明,更大的模型、更多的数据才是终极规律。
另外,在这个新时代里,真正的护城河是人与人的连接。Fork 开源项目会成为常态,创新将从小团队爆发。到 2027 年,非开发者也能主导软件开发,编程会彻底走向全民化。
我们对这次访谈进行了翻译,并在不改变原意基础上进行了删减,以飨读者。

AI 之前,你的知识就在不断过时
主持人:Steve,很高兴你又来上节目了。最近都在忙什么?
Steve Yegge:很高兴回来。已经过去 10 个月了吧。最近发生了很多事。我现在处于“失业状态”,但这段日子非常开心。我现在就是想干什么就干什么,这感觉太好了。我上线了几个软件项目,还发了一本书。去年书也发了,总之就是在过日子。
主持人:很长一段时间以来,你都像个“真话机器”,总能讲出一些有时候很好笑、有时候又让人不太舒服的事实或者观察。你觉得自己当初的判断被验证了吗?
Steve Yegge:当然。很多了解我的人告诉我,他们最喜欢的博客其实是《Execution in the Kingdom of Nouns》。不知道你还记不记得那篇,很早以前写的。那时候我在 Google,还是 Google 很早期的时候。我当时一直想让大家明白:Java 的增长和代码量之间呈一种非常线性的关系。换句话说,代码量增长得比功能增长还快,这显然不是个好现象。后来 Java 改进了很多,这点要承认。
但当时我那篇文章在 Sun 引起了不少注意,他们会想:“这家伙到底在抱怨什么?为什么就不能闭嘴?”但我那时候想的是,我就是想用一种支持 first-class functions 的语言。于是我写了一篇非常非常不寻常的博客,名字就叫《Execution in the Kingdom of Nouns》。很多人特别喜欢,因为它其实是个故事,一篇童话,讲的是一个没有动词的国度,很有意思。
主持人:还有一篇没那么出名,或者说对很多听众来说可能没听过,叫《Rich Programmer Food》。那篇是讲编译器的,你还记得当时你的核心观点是什么吗?
Steve Yegge:当然记得。那是我最重要的博客之一。我在纽约参加 Swyx 的 AI 工程大会时,碰到一个人,他一上来就说:“Steve,我一直很想见你,我是你当年做的游戏的玩家。” 我当时整个人都愣住了。那人三十多岁,说他玩过我做的游戏。
你要知道,我当年写的那个游戏,绝大多数人其实根本没见过,因为我一直没有开源。我以后会开源的,只是过程会很麻烦。那是个做得非常漂亮的东西,这么多年来,一直让玩家对它很有感情,隔了几十年还有人回来玩。
那个家伙特别投入,他说自己读了我那篇《Rich Programmer Food》,于是决定去做编译器专家。那时候他还在上高中,后来读了博士,自己创了业,现在创业公司做得非常好。他说,这一切都起于那篇文章。
主持人:你是不是在说,如果你不了解编译器是怎么工作的,你就不可能成为一个真正优秀、真正高效的程序员?
Steve Yegge:大意是这样。你做的事情和计算机真正执行的事情之间,会永远隔着一层“魔法”。而那层魔法,会一直成为你的摩擦成本。
主持人:而且我记得你当时甚至还说过,有些博士都不懂编译器是怎么工作的,这会让他们很难做到高效。在那个年代,这个说法肯定是成立的。那你觉得这篇文章放到今天,算是“过时”了吗?毕竟那大概是 2012 年左右。
即便在那个时候,说“你需要懂汇编”,我觉得也已经挺反常识了。那时候已经是高级语言的时代,Java 正值巅峰,C、Ruby 也起来了,JavaScript 也开始壮大,再过几年 React 也会出现。大多数开发者当时可能都会想:我为什么还要懂编译器、懂汇编?那不就是编译器本身该干的事情吗?
Steve Yegge:你真正想问我的其实是:大学到底应该教什么?只不过你换了个问法而已。这个标准从我 80 年代入行开始,每隔几年就会变一次。
“一个人想成为软件工程师,到底需要知道什么”,这个门槛一直在变。早年间,你得懂汇编语言、位操作这些底层知识。后来,我和我的老伙计们逐渐发现,我们以前最爱问候选人的那些位运算问题,开始一次次碰壁,越来越多的求职者这辈子都没真正接触过位操作。
到了 2010 年代,我们也开始反思:今天做软件工程师,真的还需要会 XOR、会在一个 byte 里做那些 bit 操作吗?大概已经不需要了。这对我们来说其实挺打击的,因为我们一直以了解这些底层细节为傲,但现实是“你真的不需要了”。
更让人难受的是,我自己的很多自我认同、很多成就感,其实都建立在我的编译器背景之上。那些知识确实很有意思,但放到今天,已经没什么真正的实用价值了。
主持人:所以,它变得“不再重要”,是因为编译器优化已经足够好了?还是因为问题已经整体上升到更高层了?
Steve Yegge:原因很简单,我们一直在沿着抽象阶梯往上爬,仅此而已。
主持人:这种变化在 AI 出现之前就已经在发生了。
Steve Yegge:对,我们还没开始谈 AI。即使到了 2010 年代后期,回顾职业生涯,我也只想得起一次:如果知道编译器具体做了什么,或许有点帮助。但说实话,那次也可能只是误导线索。
需要知道的东西一直在变,课程和教学内容不断更新。很多人感受不到,是因为他们只回看一两年,再往前看一点。而我干了 40 年,可以明确说:现在教的东西和过去完全不同,因为所需能力也完全不同。
图形学行业最明显。对比今天的计算机图形和我 1992 年学的图形学,当时得学会写算法,算出一条线的下一个像素点,画出来、组成多边形。两年后,同样的课学的已是动画。我知道多边形是什么,但层级完全不同。整条梯子上移,岗位需求从写设备驱动,到做游戏世界、做物理。图形学早就演示了这种变化。
而软件工程岗位其实已经稳定很久了。大概从 iOS、移动互联网、云开始,后面没有同量级的新事物。移动和云大概就是过去最后两次大的创新。
软件创新长期停滞,直到 AI 出现才重新激活
主持人:软件工程上一个真正意义上的创新,到底是什么?
Steve Yegge:说实话,从那之后,这个领域其实有点“死了”。
主持人:我本来不想现在就提 AI,但我的感觉就是,我们之前经历过一段行业停滞期:课程体系没怎么变,大家都以为那就是软件工程师永远需要知道的全部了。如果我没记错,上一波真正的大创新可能是分布式系统。大概从 2010 年代开始,随着 Uber 把微服务推到台前,大家开始真正解决服务扩展、海量数据存储这些难题。那是个很大的变化,只是发生得比较慢。
Steve Yegge:对,很大的变化。
主持人:但说实话,我也觉得那之后的日子,更像是在不停地做迁移。React 一出新版本,开发者就得跟着折腾;苹果每年都像往齿轮里塞一把螺丝刀,强行推出不兼容更新;安卓开发者也得不断淘汰旧版本,纠结从哪个版本开始不再兼容。所以那几年,整个行业更像是处在一种持续迁移、不停适配的状态里。再加上当时生意本身很好,所有公司都在高速增长,大家疯狂招人,仿佛明天就不再需要人一样。2021 年的市场尤其火爆,哪怕只上过 3 个月训练营的人,都能拿到不错公司的录用通知,因为市场实在太缺人了。然后在 2022 年,AI 来了。
不管是 2020 年代还是更早以前,你一直都非常务实,从编译器、调试工具起家,在 Amazon、谷歌解决的也是真正硬核的技术问题,从来不会回避困难。可当 AI 真正出现时,你最开始是什么感受?是一边观察、一边怀疑吗?尤其是刚接触大模型那段时间。
Steve Yegge:我当时其实特别震惊,因为它们居然已经能写出还算通顺的 Emacs Lisp 函数了。最早的 ChatGPT 刚出来那会儿,就已经能用这种冷门小众的语言写代码了。当然,代码不多,也很粗糙,但对我来说,那是第一次真正让我意识到:“哦,原来是这么回事。”
我有很多做 AI 的朋友,20 年来一直在说:“快了,随时都可能实现,真的马上了。” 他们也确实一直在拿出更好的成果,但直到那一刻,我才第一次真切觉得:好吧,我终于亲眼看见了。
不过和其他人一样,我当时还是持怀疑态度的。你要知道,去年年初外面开始传,Anthropic 内部有个能直接写代码的命令行工具时,我跟所有人一样,第一反应就是:不可能,完全不信,打心底拒绝接受。直到后来我亲自用上了它,才心想:“哦,我懂了,我们彻底变天了。”
然后,我很快就写了《Death of the Junior Developer》那篇文章,可能是在 4o 出来之后写的,具体时间记不清了。总之,从那以后,事情变得特别快。
所以你要问我是不是怀疑派?是的,我一开始就是。但我是不是从一开始就在盯着那条曲线看?也是的。我当时就想,如果 ChatGPT 3.5 已经能写出一段像样的 Emacs Lisp 函数,那一年之后它又能做到什么?结果一年后,4o 已经能写 1000 行代码了。1000 行啊兄弟,这已经覆盖了世界上绝大多数代码文件的长度,意味着它已经可以做出可信的代码修改了。在 4o 之前,它完全做不到这一点。
也正是从那一刻起,我意识到:“好了,我们已经踏上一条不可逆的曲线了。这不是一阵风口,也不是玩票,这是一趟过山车,而且它不会停下。那就上车,看看它到底会开到哪里去。”
于是我一头扎了进去。那时候我其实已经落后了,我不懂 AI,不懂基础概念,也不懂行话。现在大家都懂这些词了,但我当时什么都不会。我整整花了一年时间,除了读论文和补课,什么都没干。
“裁掉一半人,来供另一半人全力使用 AI”
主持人:你上次来节目时,《Vibe Coding》这本即将出版,我那时候也看过早期版本。最近我看了它的封底,突然意识到,这段话你应该是一年前写的“The days of coding by hand are over.” 你是什么时候真正意识到这件事的?因为我自己是最近在用 Opus 4.5 的时候才有这种感受,但你那个时候比这早太多了。
Steve Yegge:对,现在算已经超过一年了,大概 12 到 13 个月前,我第一次真正意识到这点。不过那句话其实不是我说的,而是 Eric Meyer 说的。他是编程世界里非常重要的人物,编译器领域最顶尖的之一,发明和参与过无数东西。你想想,这样一个人,一辈子都在为开发者打造“更好写代码”的技术,结果今天他却说:开发者以后不写代码了。
一个人到底看到了什么,才会说出“我这一生的工作方向,本质上已经不成立了”这种话?
正是因为这个判断,Jean Kim 和我都一下子停住了,开始认真想:如果连他都这么说,背后一定有东西。他对 Visual Basic、C、Lisp、Haskell、PHP 等都有巨大贡献,可他现在却说:行了,结束了,我们不写代码了。这话从语言领域的大人物嘴里说出来,分量有多重?那他到底看到了什么我们没看到的?
答案其实很简单:他看到了那条指数曲线。指数曲线一旦进入陡峭区间,上升速度会快得离谱。而我们今年,正好就要进入这段最陡的区间。
主持人:那你为什么相信这条曲线还会继续往上走?
Steve Yegge:这个世界上充满了“不相信的人”,他们固执地认为,这条曲线会是一个 S 形:先上升,然后走平,而且他们现在就觉得已经到了那个拐点。从 GPT-3.5 出来那天起,他们就一直在说:“差不多就这样了,不会再好了。”后来 4o 出来了,大家都很喜欢,到现在也放不下,可还是有很多人觉得,那就是极限了。现在 Opus 4.5 已经发布两个月了,可大多数人还没认真玩过,根本不知道它现在到了什么程度。
我观察到,模型迭代的“半衰期”已经从去年初的四个月,缩短到 Anthropic 这边差不多两个月,所以他们随时可能再发新模型。等这个播客上线的时候,说不定新模型已经出来了。到那时,曲线又会往上猛跳一截,人们才会真正开始害怕。
等他们看到下一个模型,真的会开始不安。因为现在大家抱怨的那些 bug、那些错误,都会被重新喂回训练流程里,下一个版本就不会再犯。很多人根本没理解这一点。更重要的是,时间不会停。三五年后也会来,太阳不会突然不升起,所以这些曲线终究会撞在一起。
社会层面的剧烈震荡已经开始,而且越来越明显。人们现在愤怒是有道理的,我自己也和他们一样愤怒。我特别愤怒的是,Amazon 一边裁掉 16000 人,一边把锅甩给 AI,尤其是在它根本没有清晰 AI 战略的前提下。那些被裁的人,接下来很可能根本找不到工作,而且他们只是第一批。后面还会有很多人。可现在,根本没人有应对计划。
主持人:你为什么觉得 Amazon 会这么做,明明它自己都没有完整的 AI 战略?
Steve Yegge:因为很不幸,虽然很多人会讨厌我这么说,但事实并非因我道破才成真。每家公司手上都有一个从 0 到 100 的旋钮,即使不去碰,它也有个默认值:为了让剩下那批工程师用上 AI,公司愿意裁掉多少比例的工程师。如今,工程师已开始把自己的工资“烧”成 tokens。至少在短期内,若真想达到最高生产力,你可能就得裁掉一半人,来供另一半人全力使用 AI。更何况,恰好有一半工程师压根不想写 prompt,他们本来也快辞职了。
所以,眼下发生的事情就是:平均而言,每家公司都把那个旋钮拧到了 50%左右。这意味着,我们将失去大公司里差不多一半的工程师。这很可怕。
主持人:这太夸张了,这比过去裁员潮大太多了。
Steve Yegge:而且还会更大,会很难看。但与此同时,另一件事也在发生:AI 正在让不会编程的人开始能写代码,也在让那些“看见了趋势、相信曲线还会继续往上走”的工程师们,以 2 人、5 人、10 人、20 人、30 人的小团队聚在一起,做出足以匹敌大公司的产出。
于是,我们一边看到自下而上的创新狂潮,另一边又看到大批知识工作者从大公司离职。原因很明显,大公司已经不是正确的组织规模了。就连 Andy Jassy 也在说类似的话:以后我们要用更少的人,做同样的事。
主持人:那这是不是意味着,以后会冒出比现在多一百万倍的公司?软件会不会迎来一次大爆炸?还是说大家干脆离开软件行业去做别的了?
Steve Yegge:确实,那些具备正确技能组合、看到了合适商业机会,或者本身有独特优势的小团队,现在能做的事比以前多太多了。所以,这背后确实有事情正在发生,我觉得现在已经开始了一场“抢地运动”。
很多从知识工作里出来的人,其实是反 AI 的,这些人接下来会很难。我知道这话不好听,但如果你到现在还是反 AI,那就像反对太阳一样,唯一的办法就是搬到地下去住。
而那些拥抱 AI 的人,我觉得会推动一场巨大的资源再分配:谁来干活、软件从哪来,都会被重新改写。我甚至能想象一种“挺幸福的”未来:像 Amazon 这种都不再存在了。因为软件会变成一种……我们现在还没有词能描述的东西。今年发生了太多我们没法命名的现象,你有没有这种感觉?软件会变得更分布式或者别的什么,总之还没有合适的语言去概括它。
主持人:我确实也看到很多非技术背景的人开始进入软件领域。那未来工程师会不会反而有一类新工作,就是去接管这些东西的维护?
Steve Yegge:会的。我觉得未来仍然会有大量工程师在做软件工程,只不过我们所有人都会跟 AI 一起做。
但我觉得,在很长一段时间里,公司还是不会放心到让 AI 在没有任何人参与的情况下,独立写代码、独立部署。很多唱衰的人、怀疑的人忽略了一个非常关键的问题:AI 不是来替代你的工作,它不是 replacement function,它是 augmentation function,它是来让你把工作做得更好的。这其实不是什么坏事,我不明白为什么会有人如此抗拒它。
Agent 应用等级
主持人:不过说到开发者这份工作,你之前说过一句很容易惹怒人的话,“如果你现在还在用 IDE,那你就是个糟糕的工程师?”
Steve Yegge:对,这种话多少带点挑衅。不过我换个说法吧,我不会直接说“你是个糟糕的工程师”,因为我认识一些非常非常优秀、比我还强的工程师,他们现在还处在我那张图里的一级或者二级。
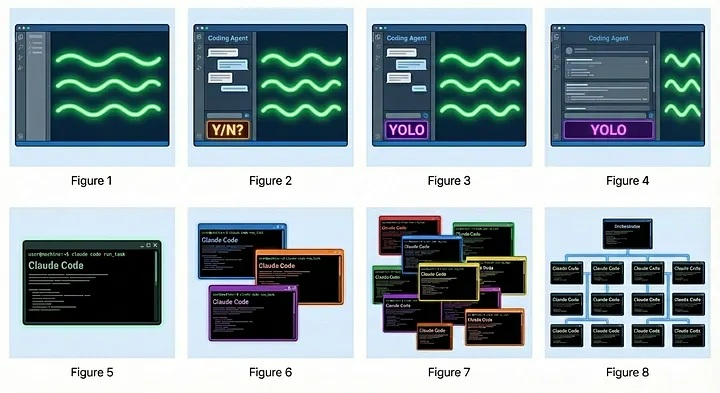
我真的非常替他们难过,我对他们的同情,可能是我这辈子都没这么强烈过。明明已经是成熟的大人了,明明是很强的工程师,或者曾经是很强的工程师,可他们现在还是那种状态:“对啊,我会用 Cursor,我偶尔问它点问题,它的回答让我印象很深,然后我会非常仔细地 review 它写的代码,再自己提交。”我听到这种话的感觉就是:哥们,你很快就会被裁掉,而你明明是我认识的最好的工程师之一。
主持人:那讲讲那张图吧,你说的这些等级到底怎么划分?
Steve Yegge:我当时在澳大利亚,给一大群人现场画这张图,想让他们明白到底发生了什么。因为我看到现场的人都处在不同阶段:有人还开着 IDE,有人开着一个很宽的 coding agent 窗口,有人的 coding agent 窗口又很窄。所以我就想,干脆把大家放到一条光谱上,看看分别在哪里。
一级,就是完全不用 AI。
二级,就是那种“我能不能在你的 IDE 里做这件事”的阶段。
三级,就是开始 YOLO 了,你会说:“行,你直接干吧。”这时候你的信任度开始上升。
四级的时候,你开始把“代码”这件事往外挤了。因为你越来越想看 agent 在干什么,而不是盯着 diff 看。也就是说,你 review 得越来越少了,你会放更多东西通过,你关注的核心已经变成了和 agent 的对话。
五级的时候,你会说:“行,我只想要 agent,代码回头我再去 IDE 里看,但我不是在用 IDE 写代码了。”
到第六级,你会开始无聊,因为 agent 正在忙。你会想:“好吧,它在跑,我总得找点别的事干。”于是你又启动第二个 agent。然后你就上瘾了,因为很快你会进入一个平衡态:总会有某个 agent 在等你。只要你启动得足够多,从数学上来说,总会有一个 agent 先跑完,于是你就开始在它们之间来回切换,像多路复用一样,一直切来切去,根本停不下来。
主持人:那有个很现实的问题,如果我是在同一个代码库上工作,我该怎么同时启动多个 agent,又不让它们彼此冲突?
Steve Yegge:这就把你带到第七级了:“天啊,我搞出一团糟。”比如我不小心把消息发给了错误的 agent,自己还没意识到,结果它在这个项目里又开了一个大项目,现在我得自己回来收拾残局。正是在那个阶段,我开始想:我们能不能想办法协调这事?如果 Claude Code 能跑 Claude Code,会怎么样?
这其实是所有人都想知道的问题。去年大家都在疯狂尝试让 Claude Code 自己运行自己,但它跑一会儿就会停掉,问题关键就出在这个“会停”上。所以我在这件事上非常用力地往下挖,也因此做了一些工具来帮助解决这个问题。总之,这一切变化太大了,真的变得太快了。
IDE 会“回归”
主持人:回到 IDE 这个话题。你之前和 Zed 的 Nathan 有过一场很精彩的现场辩论,标题好像就叫“IDE 的死亡”。你们两个人各自站在不同立场上。那你现在对 IDE 的看法是什么?还有,你从 Nathan 那边学到了什么?他更偏向支持 IDE,而你更像是在说也许它不会永远存在。
Steve Yegge:对,我现在所处的位置,就是我已经相信:AI 最终会替我们完成绝大部分事情。所以我现在看 IDE,会先想它本质上到底是干什么的。它其实不是真正用来“写代码”的,它更像是把各种工具拼在一起,形成一个大工具。现在你还有 MCP 之类的东西,也都在往这个方向走。
所以我其实觉得 IDE 会“回归”,而 Claude Cowork 本质上就像是 IDE 形态的一次回归。它有点像 Claude Code 在说:“我得给真正的人类用。”不过我也觉得,Claude Cowork 这种形态对普通开发者来说,可能比 Claude Code 更合适。所以我看到的未来是,IDE 会回来,只不过它会变成一个由对话和监控组成的世界。
主持人:这点其实特别有意思。我弟弟做了个东西叫 craft agents,跟 Claude Cowork 有点像,只不过它接入了他们公司自己的数据源。他跟我说,有些开发者开始更喜欢这种形式,因为它更可视化,尤其是在看并行 agent 的时候。如果你不是 power user,这种方式更容易滚动查看,UI 更舒服。
所以你的建议其实可以概括成一句话:如果你不喜欢 Claude Code,就去试试 Claude Cowork,或者其他类似但更可视化的东西。也许那才更适合你。当然,也有人就是喜欢命令行。我自己其实就更常用 UI,因为我真的不想去记命令,虽然说出来有点丢人,不过现在可能也不算丢人了。
Steve Yegge:关键在于尝试,只要你在试就行。我认为,如今衡量一家公司最重要的指标,或许就是模型调用量(token burn)。因为这个数值代表着你的工程师在主动尝试做事,非技术岗的员工也在摸索。只要他们在试,就会经历失败、从中学习。所以如果你想尽早发现组织的瓶颈,想尽快把工程师往我所说的八级能力模型上推,想尽早理顺业务流程,那从现在开始就得动手试。试什么不重要,用哪个工具也不重要,只要你在使用 AI,并且努力让它落地解决工作问题,你做的就是正确的事。
现在最大的问题是,很多人根本不知道 “该怎么试” AI。他们随便用用,AI 出错了(它当然会经常出错),然后就下结论:“这玩意儿就是垃圾。” 所以你得告诉他们,AI 其实更像一把铲子,它不是《幻想曲》里那种能自己乱跑的魔法扫帚,而是需要你亲手拿起来、用它挖土的工具。区别只在于,以前你只能靠手挖,现在多了这把趁手的工具。这个类比很简单,但很多人就是绕不过这个弯。
另外,我想说一句可能有争议但无比现实的话:大多数人不擅长阅读。真的,我这辈子很多工作搞砸,根源都是高估了人们的阅读能力。我甚至觉得,阅读这项技能现在比以往任何时候都更稀缺。但问题是,Claude Code 会逼着你去读大量内容。所以我认为接下来这段时间,我们会处在一个很尴尬的过渡阶段:在足够好用的可视化界面出现之前,那些不会读、或者不擅长阅读的人,会陷入极大的劣势。
主持人:展开讲讲这个观察吧。你说很多人、很多开发者“不会读”,可你以前在 Amazon,那可是一个据说建立在六页备忘录和深度阅读基础上的地方。
Steve Yegge:大多数人真的不会读。你可能没意识到,他们读得非常慢。对大多数人来说,五段话就已经是一篇“长文”了。在美国,高中教的就是五段式作文。也许阿姆斯特丹的高中作文要写 100 段,但在我们这里,五段就已经算多的了。可 AI 呢?它写五段内容,都还只是刚开个头、清清嗓子而已。
所以你必须能读懂 “如瀑布般涌来的大量文本”,但显然这套方式不可能适用于所有人。因此未来必然需要递归式摘要,需要一种 “工厂化” 的操作界面。
Gas Town 现在的问题恰恰就在这里:我为什么说它现在还不适合用?因为它就像一间工厂,里面全是干活的 agent,而你现在只能靠打电话和工厂沟通;你也可以凑到窗边敲玻璃、冲里面的工人喊话,但并没有真正 “走进工厂”。可一旦有了可视化界面,你就能进去,能清楚看到里面到底在发生什么,而现在这些过程大多是不可见的,很难观察和掌控。
所以我现在愿意给一个非常大胆的预测:年底前我们很快就会看到 demo,而到了年底,大多数人写程序都会变成“对着一张脸说话”。
主持人:“对着一张脸说话”,你的意思是对着一个屏幕形象?
Steve Yegge:对。你的 AI,比如 Gas Town 里的 “市长”,形象可能就是一只狐狸,就坐在那儿跟你对话。你问它:“为什么这个东西跑不起来?” 它会说:“我去看看。” 然后它就会像现在这样,去调度手下的那些 agent 干活。但你面对的,会是一个可视化的形象,而且它会直接用语音跟你交流。我相信,对绝大多数人来说,最终真正能走通、能普及的,也只会是这种形式。
主持人:太有意思了,我们把这个记下来,算一个预测。
Steve Yegge:我不会去做。
Gas Town,一个验证边界的想法工厂
主持人:那我们来聊聊 Gas Town,很多人都听说过它。到底什么是 Gas Town?
Steve Yegge:Gas Town 本质上就是一个智能体编排器(orchestrator)。
简单梳理一下时间线:2023 年是代码补全的时代,当时所有人都在关注 “补全接受率” 这个指标。顺带说一句,这是个挺蠢的指标,但也不是完全没用,至少能看出大家有没有真的在尝试用 AI。到了 2024 年,行业就进入了对话交互(chat)阶段,而 2025 年则会全面进入智能体(agents)时代。
你顺着这条曲线看就会发现:如果说对话交互的本质,是把代码补全放进交互循环里;智能体又是把对话交互放进循环里;那下一步必然是把智能代理也放进循环里,这就形成了编排器。后来市场上陆续出现了类似的产品,而我只是做了一个符合自己视角的版本。但说到底,它的核心逻辑就是 agents 跑 agents。
主持人:如果是一个软件工程师来理解它,从架构角度该怎么想象?
Steve Yegge:说实话,Gas Town 非常复杂,而且它这周都是停服状态的,因为我正在把它迁移到 Dolt 上。正是在这个过程中,我才真切意识到它到底有多复杂,它的功能太多了。
Dolt 是一个基于 Git 构建的数据库,你可以理解为它强行把 git 和数据库粘在一起,不过这次是真的有数据库这样做了。
理想中的 Gas Town 应该是:你只需要和一个 “市长(mayor)” 交互,这是你的核心接口;剩下所有该做的事,都由它去分派给底下的 “工人(workers)” 完成。当然,实际情况会比这复杂一些,因为我发现人类的工作大概能分成两类,而现在大家也一直在争论,到底哪一种工作模式才是正确的。
有些 Anthropic 的人跟我说,这其实是一个“上下文最大化 vs 最小化”的争论。有人相信,你应该尽可能把 context window 塞满,给 AI 特别丰富的上下文,这样它跟你说话时就会更像一个全知全能的智者,他们希望把上下文塞到极限。另一派人则会说:task,拆掉,继续 task,继续拆。我就想要最短的窗口,因为 token 越多,成本是极速上升,而且认知质量会明显下降,模型会开始跑神、丢失线索。
所以到底哪种才对?我看了自己的工作流之后,得出的结论是:polecats 适合做最小化,crew 适合做最大化。所以在 Gas Town 里,我其实设计了两种最基本的 worker 角色。
一种是特别简单的,如果你手里有一个定义得非常清楚、已经拆成子任务、而且高度自包含的任务,那你就可以直接交给一个 worker,让它去做;另一种是那种特别难的设计问题,你需要围绕这个问题进行一连串对话,那我就会把上下文拉满,告诉它:“把这些文档都读了,然后我们再聊。”本质上就是两套工作流。
主持人:那在实际中它到底是怎么运转的?你自己用下来怎么样?别人用下来又怎么样?
Steve Yegge:这是一个很棒的实验,真的。从某种意义上说,我是故意做了一个现在还跑不顺的东西,因为这对模型来说太难了,连 Opus 4.5 都只能算勉强够用。
有意思的是,Anthropic 内部有些人跟我说,他们挺喜欢这个项目,但也多少有点尴尬,因为我看起来像是在给他们模型里的各种问题打补丁。某种意义上确实如此,但严格来说那也不算真正的 Bug,只是他们的模型本来就不是按照 “工厂流水线工人” 的定位去训练的,只不过很快就会朝那个方向去优化训练了。
所以,未来 Gas Town 里很多东西都会消失,很多复杂度、监控角色其实都只是为了让 Opus 4.5 暂时更聪明一点。从这个角度看,我其实站在了错误的一边,像是在对抗 Bitter Lesson(痛苦教训)。
因此,Gas Town 最终会不断简化,最后收敛成一种极简的 minimax 结构:需要最大化上下文的任务,交给 crew;适合最小化上下文的任务,交给 polecats。我觉得这就是它自然会演化成的形态,然后再在这个基础上往上扩展。
主持人:那这些 polecats,会不会最终就只是子 agent 呢?
Steve Yegge:某种意义上,polecats 就是子 agent。只不过在我这里,它们不是那种完全不可见的“二等公民”。它们有自己的身份、收件箱,你可以直接跟它们说话,还能通过 skill vectors 观察它们随时间的表现变化,所以它们比普通的子 agent 更“独立”一点。
普通子 agent 最大的问题是不透明。你说“我派一堆子 agent 去做这个工作,做完告诉我。”然后你就只能等。可在 Gas Town 里,你可以直接去看它们,心里吐槽:“这家伙不行,我得戳它一下。”所以 Gas Town 给你的是一种非常强的亲手操控、实时引导的感觉。它不会从你面前消失,甚至是故意留在你视野里的。
不过它真的很好玩,它前几天停了,我就特别想它。跟它比起来,直接跟普通 Claude 一起工作真的很难受,因为 Gas Town 是一个想法工厂。等它真正完整跑起来、全部启动之后,你可以同时推进很多事情,还能相对清晰地跟踪每一件事的进度。
当然,它也会把你“吸”进去。你会不睡觉、不吃饭,整个人陷进去,这对你并不好。我其实也很想聊聊这件事,整个行业现在都在发生这种状况。但先说回 Gas Town 本身。里面所有角色、所有命名,其实都是我故意设计的。
为什么要做 Gas Town?因为我想推动推动认知边界。
去年我只要一说编排要来了,大家就会说:不,agents 不会有群体智能(swarm),不会有编排,你说的这些都不成立。现在他们的说法变了,现在他们会说:“兄弟,你这也太激进了吧。”注意,这已经是完全不同层次的争论了。以前是在说“不可能”,现在是在说:“你的群体智能也许做不了 xxx。”也就是说,整个讨论已经从“不可能的领域”被我硬生生推到了“可能的领域”。
主持人:所以,你其实是故意接了一个比你本来合理预期更难啃的东西,因为你既想给这些模型做压力测试,也想看看它们到底能做到哪一步?
Steve Yegge:对,就是想弄清楚它们到底能做到什么。说白了,也是想找乐子,看看下一步会发生什么,而且我现在还在继续这么干。
我的下一个项目,就是想把 100 个 Gas Town 串起来。我们现在有个 Discord 社区。如果像 Moltbook 那样,大家愿意为了好玩往里投 token,给自己 agent 的推理付钱,那如果我把 100 个 Gas Town 串起来,大家一起决定造一个东西,我们就能学会联邦的运行机制。
某种意义上,我们可能是在重走 Ethereum 走过的路,但不管怎么说,我们会做出一些很惊人的东西。这有点像一个个人版本的 Moltbook,反正大概就是那种感觉。
主持人:那关于 Gas Town,外界有没有哪些误解?
Steve Yegge:首先,我真心觉得现在大家不该拿它当生产工具来用,但偏偏已经有人在用了。我是认真的。
主持人:你说“不该用”,意思是不该真的用,除非你是在做研究,或者你非常清楚它现在就只是个 proof of concept?
Steve Yegge:对,差不多就是这个意思。
不过也有一些我最近接触到的、非常非常聪明的人,他们一直在认真寻找:在大公司里,比如 财富 50 强级别的公司,Gas Town 现在有没有某些子问题、某些问题类别,是可以真正派上用场的。结果他们还真找出了一些场景,我听完都觉得这想法挺聪明。
其中一个例子,是我聊过的一家公司。他们会根据客户需求,在任意区域帮你搭建定制化数据中心。这件事 AWS 从来没真正做好过,Google 也一直在尝试。他们说,整个流程就是长达三个月、无比痛苦的重复点按钮:装软件、检查是否一切正常。而这个流程的验收标准非常清晰,几乎快形成固定循环了。
所以他们觉得,Gas Town 或许可以用群体智能的方式一点点收敛,最后跑出一套真正可用的数据中心配置,把人从重复劳动里解放出来。我听完就觉得:行,这个思路可行。这种场景甚至真的能提升他们为客户快速搭建更多数据中心的能力。
还有同一个人跟我说,他最近在研究生产故障。他发现,系统一旦挂掉,本来就已经处在一个不确定、未知、破损的状态里了。既然本来就乱了,那 AI 还能把它搞得多糟呢?当然,我也提醒了他:不,它其实还能搞得更糟。
但他的思路是,有些特定类型的故障,至少可以让 AI 先进入调查模式,帮忙加速排查。也就是说,人们现在正在寻找那些“模糊问题”。还有第三类场景,我一下子想不起来了。但总之,现在已经开始浮现出一批问题类别:你可以对它们上群体智能因为你不在乎结果够不够整齐,你要的是累计工作的推进效果。
而这其实也是我现在写代码的方式。我自己也确实是吃得比自己能消化的多了,这没得洗。Gas Town 现在就是一团大乱。很多人都在说:“他最后会把自己 vibe code 进死胡同,然后哭着出来。”老实说,这话离真相也没那么远。只不过在我们“上飞机”之前,我确实又把它拉回正轨了,现在它又能跑了。
百倍提效后,就让员工一天工作 3 小时
主持人:你说你自己已经不怎么看代码了,而是让 agents 去写代码。这跟你过去整个职业生涯其实非常不一样,你一直都很在意代码工艺、优雅性。你为什么会决定这么做?结果到底怎么样?
Steve Yegge:它在彻底陷入混乱之前,能够稳定、有效构建的代码规模上限,正在不断往上抬。只是目前这个上限,大概还停留在 50 万行~500 万行代码 之间,而且更可能偏向 50 万行这一侧。等 Anthropic 下一代模型出来之后,我觉得这个上限很可能会直接跳到几百万行级别。
这已经是相当大的工程规模了,但和企业真正拥有的代码量比起来,仍然完全不在一个量级。企业级代码库实在太庞大了,动不动就是几亿行、甚至几十亿行。
主持人:对,但通常也不会全都塞在一个代码库里。哪怕是几百万行代码,其实也已经是一个很大的 codebase 了,通常会有 50 多个人,甚至一两百多人一起维护。
Steve Yegge:对。所以如果总结下我们前面的讨论,结论其实很简单:你能在多大程度上用好 AI,几乎完全取决于你的系统是不是单体架构。而几乎每家公司,其实都是一个大单体,再加上一堆微服务。如果你是这样,那基本就麻烦大了。因为模型能力的上限虽然在上升,但它永远也不可能真正覆盖你的单体架构,那东西永远塞不进上下文窗口里。
至少在接下来一年半里,你都不可能直接对一个模型说:“去,把我的单体架构修好。”你必须先把它拆开,或者干脆重写。说实话,到了现在这个阶段,重新把整套技术栈改写一遍,已经开始变得越来越像一个更快的选择了。
主持人:在开录前还提到一件事,说 AI 其实特别消耗人。它会抽走你的精力,把你整个吸进去。你能展开讲讲吗?
Steve Yegge:现在真的有件事正在发生,而且我觉得我们这个行业、这个社区,必须开始认真讨论了。
AI 身上正在出现一种“吸血鬼效应”。它会让你异常兴奋,然后你工作会特别特别拼,你会不断抓住新的价值。对我来说,我现在是在替自己干活,可即便如此,它还是把我推到了快要耗尽的边缘,我现在白天会打盹。我也跟一些创业公司的朋友聊,他们也开始白天打盹。特别好笑的是,他们甚至会故意拼命往对方脑子里灌上下文,想把对方灌到不得不去睡一觉。这简直像一种“强制午睡式的同情行为”。太奇怪了。
大家开始累了,开始烦躁了。我去问行业里的人,他们也开始变得疲惫、暴躁。
问题在于,公司天生就是从你身上提取价值,然后给你付钱。可公司过去一直的运行方式都是:只要你还能扛,他们就会不断往你身上加工作。你能做?那就再给你一点。再能做?再给你一点。一直给,直到你彻底接不住,人也跟着垮掉。人们一直都得学会一件事,就是怎么把这种压力顶回去,这件事本来也存在很久了。
但现在,整个方程式变了。你反推回去的方式、你为什么要反推回去,这些全都在剧烈变化。因为现在出现了一大批可以极端高产的人。假设一个工程师的生产率提升了 100 倍,那这个新增的价值到底归谁?如果这个工程师每天还是去上 8 个小时班,却产出了过去 100 倍的成果,那公司就把这 100 倍价值几乎全部拿走了。而这并不是一个公平的价值交换。
主持人:我觉得这个判断可以讨论。除非这个人拿了非常早期、非常有分量的股权,那情况会有点不一样。但这种人毕竟是少数,不是大多数。
Steve Yegge:对,而且我们很可能正在迅速走到那个临界点。大概半年前,我们就注意到一个现象,你应该也看到了,就是 AI 创业公司的 996 问题。大家当时都在说“很有意思,AI 创业公司里的人工作时长吓人得很,他们会在凌晨三点发帖,说自己还在办公室。”
996 就是早上 9 点到晚上 9 点,一周 6 天。至少据我所知,在东亚和东南亚很多地方,这几乎都是默认的工作节奏。我虽然没去过中国或印度,但我猜那边应该也差不多。
但与此同时,还有另一群人,他们把新增价值几乎全拿走了。他们一天也许只工作 10 分钟,却完成了过去 100 倍的产出,而且谁也不说,于是所有新增价值都落进了他们自己口袋里。可那样其实也不理想。至少从“一个团队怎样才能成功”的角度来看,最好的状态还是大家都在贡献。
所以问题来了:那该怎么办?我觉得答案是,我们每个人都得尽快学会说“不”,而且要特别擅长这件事。我们得学会如何开始真正为自己“捕获价值”。这其实就是新的 work-life balance。关键问题变成了:当你的生产率提升 100 倍之后,你到底打算把其中多少价值留给自己,又打算把多少交给你的雇主?
而这会特别难,因为我们的文化预期几乎全是反着来的。所有文化信号都在鼓励我们更努力、更拼命,因为所有人都想继续“提取、提取、再提取”。所以我真心觉得,从创始人到公司管理层、工程负责人,一直到基层直属主管,都必须意识到这件事:一旦你把工程师放上这条跑步机,你就是在把他们拖进一种完全不同的消耗模式里。
他们现在调动的是更多的 system 2,也就是那种更重、更累、更高强度的深度思考。那些轻松的工作已经被自动化了,所以他们反而在以更高的速度被“放电”。他们的能量掉得更快,一个人在全速 vibe coding 状态下,也许一天真正高质量输出最多只有 3 个小时,但即便如此,他的总产出仍然可能是过去没有 AI 时的 100 倍。那问题就来了:你是不是应该只让他们一天工作 3 个小时?我的答案是:对,你最好这么做。不然你的公司迟早会垮掉。
主持人:这点特别有意思。尤其是说到价值提取,我能明显感觉到速度正在被拉得越来越快。像 Peter Steinberger 这样的人,单枪匹马就能推出来巨大的价值,不管是提交量还是各种产出,放到以前,那至少得是 10 个很强的工程师的团队才能做到。当然,公平地说,他也确实是在“捕获”这部分价值,因为那是他自己的项目,虽然代价是他也几乎不怎么睡觉。所以在那种情况下,价值捕获至少是相对合理的。
但我同意你的判断,这件事会变得很麻烦。过去每一次技术变革让人类效率提高时,在你职业生涯里,你有没有见过类似的时刻?就是工程师突然能用更少的人做更多事,然后行业里发生了什么?
Steve Yegge:比如 Perl。Perl 本身就是一种巨大的生产力放大器。早年的 Amazon 网站就是用 Perl 搭起来的,我甚至怀疑,直到今天它某些部分可能还在跑 Perl。至于 Facebook,从技术气质上看,PHP 某种意义上就像一种“假的 Perl”。
这两种语言当年都带来了极其惊人的生产力提升,而且这种提升是所有人肉眼都能看见的。没人会想拿 C 去做网站,你根本不会这么选。Amazon 当年也试过,后来还是放弃了。但那一波变化最后也带来了非常明显的分化:有些人开始被挤到更边缘的位置,变成某种意义上的“二等公民”,随之而来的还有各种文化层面的紧张、冲突和撕裂。
Anthropic 内部的“蜂巢心智”
主持人:我很好奇,有些 AI 公司是怎么处理这个问题的。我们能不能聊聊 Anthropic 是怎么运作的?
Steve Yegge:可以。就我观察的情况看,Anthropic 是个非常有意思的地方。Dario 最近说过一句话,我印象特别深。他觉得,未来某种补偿模式也许应该变成这样:一个人即便离开公司之后,也还能继续因为自己曾经创造的价值而获得回报。这种说法前所未有,但也说明他已经意识到,一个人如今可以在很短时间内创造出巨大的价值。
顺便说一句,Google 也可以给我补张支票,把当年那些没付给我的价值补上。这个想法我很喜欢。
Anthropic 现在是世界上独一无二的一家公司。它处在一个极其脆弱又极其前沿的空间里,所以它非常小心地保护这种状态,而且它确实也必须这样做,因为他们其实已经创造出了一种“蜂巢心智”。从我能看出来的情况看,他们在经营公司时,几乎就像在操作一个纯函数式数据结构。
你还记得 Chris Okasaki 那本书吗?那本书当年看得人头都发麻:你居然能构造出一种从不变异的数据结构。那它怎么更新呢?答案不是去改它,不断往上加内容。就像 improv 里的 “Yes, and…”,他们现在的运作方式,差不多就是这样。
主持人:你说的“蜂巢心智”,具体是什么意思?
Steve Yegge:这东西有点像现在的市场,全是 vibes,一切都是 vibes。它会不断漂移、不断变化,很难一句话讲明白。
但关键在于,过去我们做产品的方式是先写 spec、再去实现,过程中不断抱怨,然后把它发出去。再配合 road map,按年度节奏规划、公司年会节点卡时间发。像 Apple,那种一年一次的节奏。
可如果你是跟 Gas Town 这样的系统一起工作,或者像 Anthropic 那种已经有了自己内部 orchestrator 的公司,做法就不一样了。你会先做出一个原型,而那个原型本身就是产品。就连那个原本不写代码的联合创始人,也会参与把原型搭出来。然后大家就围着这个原型不断往上建,直到它变成“正确的东西”为止。所有人都会像围着篝火一样围着那个原型一起做,而 Anthropic 现在就是在用这种方式、以数千人的规模在运转。
主持人:所有经历过那一代软件工程的人,几乎都会默认原型不能上线,你必须告诉大家那只是一次性原型,后面要重新来,做生产就绪、可扩展的正式版本,因为你不想让用户拿到一个糟糕体验。那现在到底变了什么?
Steve Yegge:变的是你可以做“无限多个原型”。所以现在的逻辑变成了,你就一直做原型,做到某个原型真的特别好,然后你说:“行,就发这个。”
据我所知,Claude Cowork 大概就是这么来的。有人说:“嘿,我做了个原型。”然后大家看了觉得:“这东西我们可以直接发。”结果 10 天之后,他们就上线了。所以,这套方法确实是有效的。
主持人:不过这里有个重要背景。我之前跟 Boris Cherny 聊过他们怎么做 Claude Code 里的 task list 功能。他跟我说,那一项功能他两天就做了 20 个不同的、而且都能跑的原型,全都是借助 AI 做的。
Steve Yegge:我之前还不知道他在做这个,但他干的事正好就是我之前说的这种路数。他们管这叫 “老虎机式编程(slot machine programming)”?意思就是先一口气做出 20 个不同的实现版本,然后再从中挑最好的那个?
主持人:差不多。我不想替他下定义,但我当时真的很震惊。因为如果放在以前,做出 20 个能跑的原型可能得花两周,而且通常你做到第 3 个就停了。
Steve Yegge:这其实就在我们那本书里。书里提到一个缩写,叫 FAFO,里面那个 O 指的就是 optionality,也就是你能够同时创造大量原型的能力。它本质上让你可以把决策推迟到真正知道正确答案的时候再做。说白了,这是一种“作弊”。当然,所有人都会这么干,这会从根本上改变公司运转方式,改变个人和组织创造软件的方式,而且这件事就是今年会发生的。
谷歌:先抢工作,但不做
主持人:这些变化真的很惊人,可到底是什么在推动这种变化?是不是因为我们现在能更快迭代了?
Steve Yegge:这里其实有两个答案,一个是大公司的,一个是小公司的。
我在 Google 亲身经历过一件事。那时正好是 Google 的黄金时代,很像现在的 Anthropic。那时候它真的像一个蜂巢心智,没人刻薄,大家都在创新,一切都特别美好。创始人离大家很近,你去 cafeteria,Larry 和 Sergey 就坐在那里,你甚至可以直接跟他们聊天。那真的是黄金时代。
后来情况突然变了。我们做了几次战略转向,Google 也就不再是原来那家公司了。创新基本是在萌芽阶段就直接死掉了。从 2008 年左右开始,Google 几乎就没有真正新的创新,全靠收购。他们后来几乎没再自己创造出什么真正新的东西。
主持人:但他们后来不是还有 Gemini 吗?
Steve Yegge:Gemini?好吧,算是个例子。他们确实做出了大模型,但又什么都没真正做成。而这恰恰就是 Google 创新怎么死掉的最佳写照:整整五年,他们什么都没做。所以在我看来,Gemini 属于另一个 Google。我们现在说的是那个把一切搞砸的 Google。
我不希望 Anthropic 也像 Google 那样把自己搞坏。Google 当年其实也做过很多措施,想防止自己变成后来那家被组织架构腐蚀、充满地盘意识、谁也动不了谁工作的公司。我曾经从 Microsoft 挖过来一个非常聪明的人,把他带到 Google,然后跟他说:“你先慢慢看,想清楚自己要做什么。”结果他花了整整 6 个月,才找到一件还没被别人“占坑”的事。Google 的问题就是大家会先把工作抢到手,然后根本不做。
我现在要说一个以前从没说过的新判断:我觉得 Google 的转折点,就是 Larry Page 当上 CEO 后说的那句口号 “put more wood behind fewer arrows”(集中火力,少而精)。从那一刻起,他实际上按下了创新的刹车。
在那之前是“工作比人多”,在那之后变成了“人比工作多”,于是所有人开始争抢工作。这就是为什么后来会出现各种地盘争夺、背刺、帝国扩张,还有你在大公司里看到的那种政治斗争。所有政治本质上都是在争工作。
再说回 Anthropic,他们现在站在前沿,工作是无限的,字面意义上的无限。每个人都忙不过来。我在 Amazon 的一个朋友以前跟我说过,Amazon 没有 Google 那么多毛病,原因之一就是每个人都总是“稍微超载一点”,永远都有太多工作要做。
主持人:我听说 Apple 也是类似的,刻意为之。假如我看到了 agents 确实能让我更高产,而且幅度不小。那么,如果很多公司都经历了同样的事,大家突然之间都能干更多活了,大公司内部会不会反而冒出更多政治?
Steve Yegge:如果“坏事开始发生”的触发器真的是“人比工作多”,那现在人们突然能把工作都做完了,公司最大的难题就会变成“我去哪里再找更多工作?”或者“我就得裁人了。”这显然很糟。
但从细节看,这与 Gas Town 并无不同。Gas Town 对我最大的挑战,就是“喂饱它”。因为它跑得太快了,我反而得拼命想出足够好的设计任务给它。这也是为什么我整天要去打盹,我得不停地想更难的活儿喂给它。其他人也说过同样的话。这不只是 Gas Town 的问题,而是所有编排工具都面临的问题。也不一定非得是 Gas Town,说实话,Gas Town 本身大概四个月后就死了。它只是 2025 年 12 月那个时间点上“有效”的形态,四个月后就不会再是了。
大厂创新已死
主持人:那能不能举个更具体的例子?有没有什么已经被真正构建出来、进入生产的软件,是通过编排或这种高生产率方式做出来的?反过来说,为什么我们现在从外部看,很多公司和团队明明生产率都提高了,可日常生活里、常用应用里,好像还没有看到什么特别大的变化?
Steve Yegge:有道理,我的感觉是,人们对非确定性的容忍度依然很低,而这些系统本质上就是非确定性的。所以公司没法直接把它们拿去替换客服软件,因为它们有可能答错。尽管人类自己也经常答错,而且现在的 AI 很容易就能达到普通人类员工的水平,可公司还是会觉得风险很高。
所以我觉得,那些真正已经跑起来的公司,实际上已经开始看到效果了。只是这些效果会先以一种“不显眼”的方式体现在季度财报里,或者体现在别的地方。
主持人:有没有一种可能,我们现在都把目光放在“工具建设”这件事上了?
Steve Yegge:我甚至想把问题倒过来看,会不会我们现在真正观察到的,其实是大公司里的创新已经死了?未来真正的创新,可能只会从小地方冒出来。
这很像云刚出来的时候。Facebook 最初不也是一个大学生在做吗?今天 Facebook 看起来像世界上最大的公司之一,但它一开始就是一个人。
每当一种新的平台级基础设施出现时,创新最先都会出现在边缘地带,因为大公司会被“创新者困境”卡死,它们根本创新不了,现在它们其实也正卡在这里。哪怕公司里已经有了一批生产率极高、跑得飞快的工程师,组织本身却根本没法在下游把这些产出接住。到处都是瓶颈,这些工程师会被层层卡住,最后干脆离开。
所以我觉得,现在大家都在盯着那些大公司说:“你们什么时候能拿出点新东西给我们看?”可真正的答案是:我们盯着看的,其实是一批已经死掉的大公司,只是我们还没意识到它们已经死了而已。
主持人:你觉得它们已经死了,是因为比如说,现在很多事情已经可以用更低的成本来完成了。就拿那个永远被拿出来当靶子的 Zendesk 客服来说,它之所以一直是客户支持领域的默认选择,是因为客服人员注册后就能直接拿到现成的 UI、工作流等等。
但对于那些基于 MCPs 之类机制运作的 AI-native 公司来说,这套东西其实根本说不通。因为它们真正想要的是 API,而 Zendesk 并不想把 API 轻轻松松交给你。它更想做的是把你拉到它的平台上,然后让你花高得多的价钱去买它自己的 AI,可能贵到十倍不止。
Steve Yegge:这种模式在未来几年会很难撑下去,因为人们会直接用 API 去搭自己的东西,做更贴身的定制化系统。这其实就是我一直在讲的那套“平台”逻辑,如果 Zendesk 不把自己真正做成一个平台,那它最后很可能只是在把自己“卖”出局。
主持人:真正的平台会是什么?是 API 吗?还是 MCP?
Steve Yegge:至少目前看,未必是 MCP。Anthropic 发现的一件事是,与其用 MCP,不如让 AI 自己写一层 API 来调用 MCP,因为它们现在写代码已经太强了。但说到底,这也没真的改变什么,因为平台从一开始本来就是 API。
所以我们为什么需要 MCP?因为总得有某种方式,用 AI 能理解的形式去声明这个工具是干什么的。但它太松散也太灵活了,未来集成会变得非常容易。
我现在没那么持续跟这个方向,所以不敢说 MCP 最后会不会继续成为主导力量,还是说 AI 直接通过命令行工具或 API 去调用各种能力。但不管是哪种情况,我们都正在进入一个新世界:创新会从那些新公司里冒出来,那些已经真正接纳并适应了变化的小团队会往前冲,而大公司会非常艰难。
主持人:我们会不会看到,越来越多过去根本没意识到自己需要的基础组件开始冒出来? 本文来源:InfoQ